
Why Vector Database?
AI applications handle a vast amount of data. And for advanced AI applications e.g. image recognition, voice search, fraud detection or recommendation engine, the vastness of the data further increases. Vector DB is used to handle such vast and intricate data. It enable users to use semantics searches to find an object. For example you like a nice flower plant in the Ooty Garden and want to find the name of that flower. You just need to type the detailed description of the flower in the AI powered search engine – “A pink coloured flower with darker pink spots on it’s petals, and the yellow colour colour middle part of the flower. Found this flower in Ooty Garden. Helo me to find the name of this flower?” The engine will fetch you the name. This is an example of how semantic search can help businesses, such as e-commerce, retail, and marketplaces, to drive customers toward the ‘action’ or purchase. This would have been challenging with traditional keyword searches. Behind the success of the semantic search, vector databases is playing the key role.
Use Cases of Vector DB
1. Enhancing retail experiences: It enable the creation of advanced recommendation systems. The product suggestions not just based on past purchases, but also by analysing the similarities in product attributes, user behaviour, and preferences.
2. Financial data analysis: It excel in analysing the dense intricate financial data & helping financial analysts detect patterns crucial for investment strategies. By recognising subtle similarities or deviations, they can forecast market movements and devise more informed investment blueprints.
3. Healthcare: By analysing genomic sequences, vector databases enable more tailored medical treatments, ensuring that medical solutions align more closely with individual genetic makeup.
4. Enhancing natural language processing (NLP) applications
5. Anomaly detection: Spotting outliers is as essential as recognising similarities. Especially in sectors like finance and security, detecting anomalies can mean preventing fraud or preempting a potential security breach. Vector databases offer enhanced capabilities in this domain, making the detection process faster and more precise.
Features of a Good Vector Database
1. Scalability and adaptability: A robust vector database ensures that as data grows – reaching millions or even billions of elements – it can effortlessly scale across multiple nodes. The best vector databases offer adaptability, allowing users to tune the system based on variations in insertion rate, query rate, and underlying hardware.
2. Multi-user support and data privacy: Vector DB prioritise data isolation, ensuring that any changes made to one data collection remain unseen to the rest unless shared intentionally by the owner. This not only supports multi-tenancy but also ensures the privacy and security of data.
3. Comprehensive API suite: Offers a full set of APIs and SDKs to ensures that the DB can interact with diverse applications and can be managed effectively. Leading vector DB, like Pinecone, provide SDKs in various programming languages such as Python, Node, Go, and Java, ensuring flexibility in development and management.
4. User-friendly interfaces: Reducing the steep learning curve associated with new technologies, user-friendly interfaces in vector databases play a pivotal role. These interfaces offer a visual overview, easy navigation, and accessibility to features that might otherwise remain obscured.
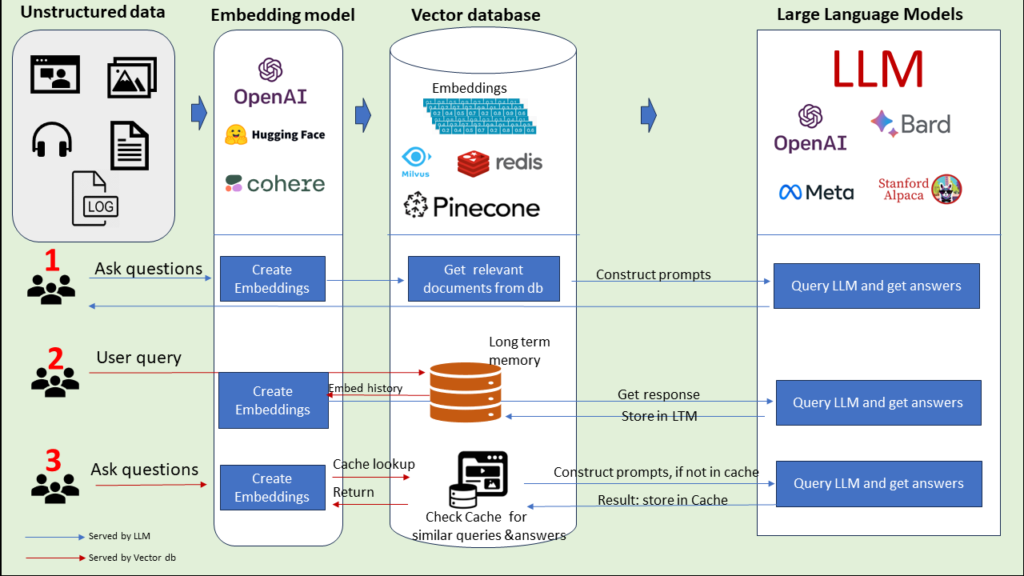
1. As a knowledge base to provide ‘context’ from the enterprise aka RAG ( Retrieval Augmented Generation). In this case, Vector DB acts as a knowledge extension for LLM’s and can be queried to retrieve existing similar information (context) from the knowledge base. This also eliminates the need to use sensitive enterprise data to train or fine-tune LLM. Every time a question is asked:
· Question gets converted to LLM-specific embedding.
· Embedding is used to retrieve relevant context (or documents) from the Vector database
· LLM Prompt is created with the help of this context.
· Response is generated. Enterprise-specific context helps LLM to provide accurate output.
Use cases: Document discovery, Chatbots, Q&A.
Key benefits: Avoids using sensitive data for model training/fine-tuning. Cheaper than fine-tuning LLMs. Almost real-time updated knowledge base.
2. Acting as long-term LLM Memory. This helps to retrieve the last N messages relevant to the current message from the entire chat history which can encompass multiple simultaneous sessions and historical interactions. This also helps to bypass context length (tokens) limitations of LLM and gives more control in your hand. Here key steps are:
· User asks a query.
· System retrieves stored embedding from the vector database and pass on to query LLM
· LLM response is generated and shared with the Use. Also, response embedding (with history) is stored in a vector database.
Use cases: Knowledge discovery, Chatbots.
Key benefits: Bypass token length limitations of LLM and help with conversation topic changes.
3. Cache previous LLM queries and responses. When a query is fired, create embedding and do a cache lookup before invoking the LLM. This ensures quick response and money saved on computation as well as LLM usage. Here key steps are:
· User asks a question.
· Embedding created and Cache lookup performed.
· If information is available in Cache, a response is provided.LLM not invoked.
· If information is unavailable in Cache, LLM is invoked, and the response is stored in the Cache.
Use cases: All use cases such as Document discovery, Information retrieval, Chatbots, and Q&A.
Key benefits:Speeds up performance, optimizes computational resources and LLM invocation cost.
This list doesn’t end here. Vector database work like a buddy with LLM and helps you to optimize security, cost, and performance across use cases. Depending on your business and specific use cases, solution need to be designed.
If you are considering investing in a Vector database or planning to use the feature available in an existing database like Radis, you should think and plan to address multiple system design concerns related to vector databases and LLM use cases, including but not limited to:
· Keyword vs Semantic search: Keyword search is good for finding results that match specific terms, while the semantic search is good for finding results that are relevant to the user’s intent. You may need a strategy to leverage the best of both, depending on your use cases.
· Creating embeddings with cost and time efficiency at scale,without paying too much for GPUs (vs CPU) but avoiding latency in the system.
· Strategy around Multimodal search which allows users to search for information using multiple modalities, such as text, images, audio, and permutation combinations.
· Also, think about whether your use case needs precise search results or explorative results.
· Whether to invest in a new vector database or use dense_vector in Elasticsearch, open search, or Solr?
· Integration with existing ML models and MLOps. How to ensure models will be performing best even at an increased scale? You may need to relook at the data pipeline and enable real-time streaming (Kafka/Kinesis/Flink) as real-time or near real-time predictions, fraud detection, recommendations, and search results would need them.
· There are business use case-driven issues to consider too: for example in a marketplace scenario, if a seller adds a new product, how the system treats it with respect to search and recommendations?
· Many more…
With the technology still evolving, it’s beneficial to have experts that can guide you through system design while preventing redundant future costs.
What is Vector Database?
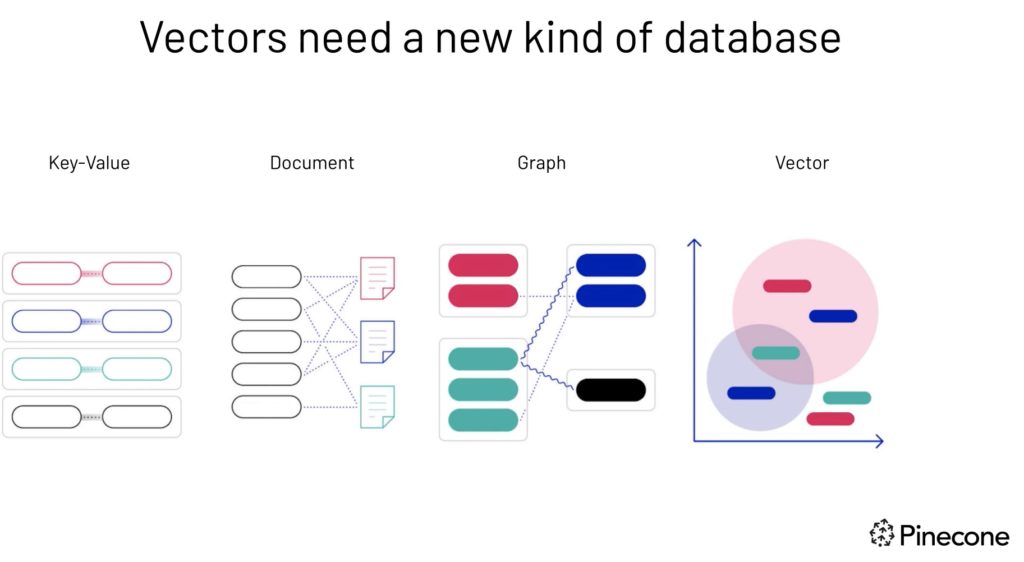
Vector need a new kind of DB [Image Source]
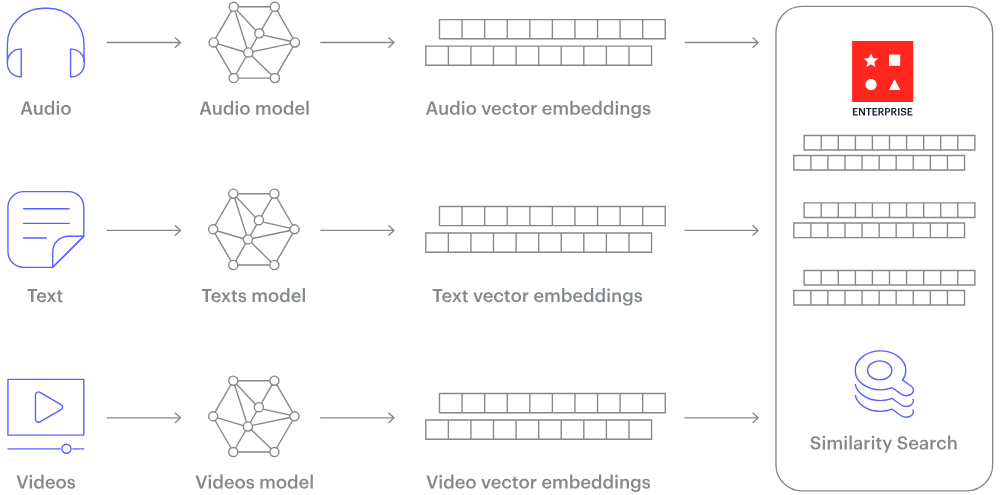
How Vector DB Work [Image Source]
Unlike traditional databases that store scalar values, vector databases are uniquely designed to handle multi-dimensional data points representing certain qualities or characteristics of data, often termed vectors or embeddings. These vectors, representing unstructured data (text, images, videos) in numerous dimensions, can be thought of as arrows pointing in a particular direction and magnitude in space. The number of dimensions in each vector varies from just a few to thousands depends on the data intricacy and detail. The processes like ML model, word embedding or feature extraction technique are used to convert data to vectors. Vector DB uses a special technique called Approximate Nearest Neighbour (ANN) search, which includes methods like hashing and graph-based searches.
Vector databases with LLMs can handle large-scale, high-dimensional data, enabling more nuanced, context-aware, and efficient natural language understanding applications.
Keyword vs Semantic search
Relational DB store items with pre-defined relationships between them. These databases typically organize data in tables with columns and rows. This is known as structured data and is generally easy to search and analyze. Traditional keyword search is good for finding results that exactly match the specific terms.
In contrast, the semantic search is good for finding results that are relevant to the user’s intent but unstructured. Vector DB swiftly and precisely locate and fetch such data based on their vector proximity and resemblance. We can make a strategy to leverage the best of both, depending on our use cases.
What is Embedding?
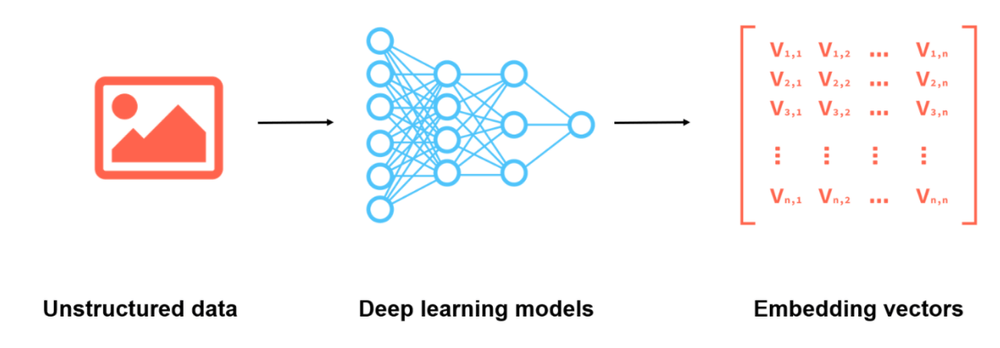
Embedding [Image Source]
Unstructured data, such as text, images, and audio, lacks a predefined format, posing challenges for traditional databases. Such data get transformed into numerical representations using embeddings. Embedding is like giving each item, whether it’s a word, image, or something else, a unique code that captures its meaning or essence. This code helps computers understand and compare these items in a more efficient and meaningful way. Think of it as turning a complicated book into a short summary that still captures the main points. This embedding process is typically achieved using a special kind of neural network designed for the task. For example, word embeddings convert words into vectors in such a way that words with similar meanings are closer in the vector space. This transformation allows algorithms to understand pattern, relationships and similarities between items.
Popular Vector Databases
1. Chroma
Open-source embedding database makes it easy to build LLM apps by making knowledge, facts, and skills pluggable for LLMs. Explore Chroma DB tutorial
- Feature-rich: queries, filtering, density estimates, and many other features
- LangChain (Python and JavScript), LlamaIndex, support available
- The same API that runs in Python notebook scales to the production cluster
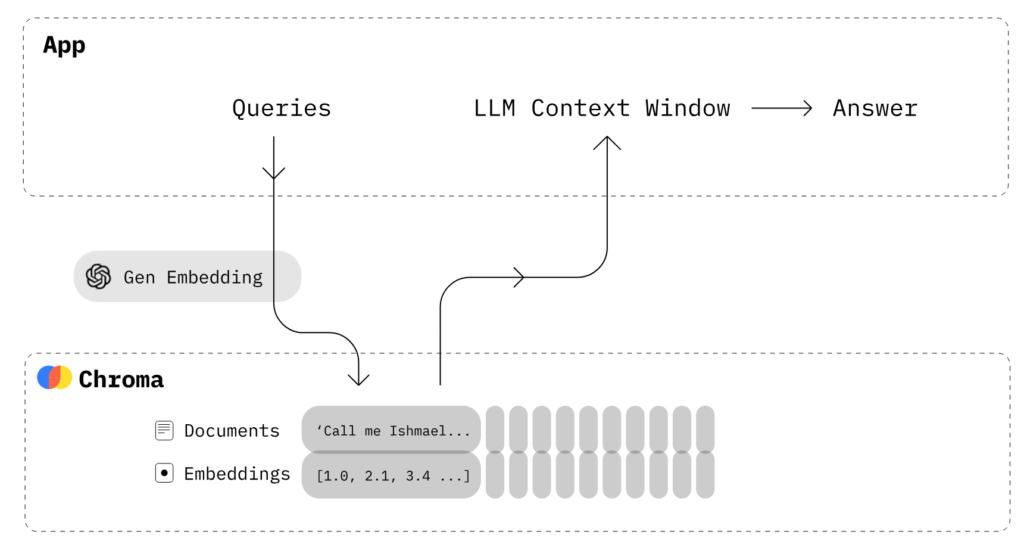
Chroma [Image Source]
2. Pinecone
Pinecone is a managed vector database platform that has been purpose-built to tackle the unique challenges associated with high-dimensional data. Equipped with cutting-edge indexing and search capabilities, Pinecone empowers data engineers and data scientists to construct and implement large-scale machine learning applications that effectively process and analyze high-dimensional data. Key features of Pinecone include :
- Fully managed service
- Highly scalable
- Real-time data ingestion
- Low-latency search
- Integration with LangChain
To learn more about Pinecone, check out this Mastering Vector Databases with Pinecone Tutorial by Moez Ali on Data Camp.

Pinecone [Image Source]
3. Weaviate
Weaviate is an open-source vector database. It allows you to store data objects and vector embeddings from your favorite ML models and scale seamlessly into billions of data objects. Some of the key features of Weaviate are:
- Speed. Weaviate can quickly search ten nearest neighbors from millions of objects in just a few milliseconds.
- Flexibility. With Weaviate, either vectorize data during import or upload your own, leveraging modules that integrate with platforms like OpenAI, Cohere, HuggingFace, and more.
- Production-ready. From prototypes to large-scale production, Weaviate emphasizes scalability, replication, and security.
- Beyond search: Apart from fast vector searches, Weaviate offers recommendations, summarizations, and neural search framework integrations.
If you are interested in learning more about Weaviate, check out our Vector Databases for Data Science with Weaviate in Python webinar on DataCamp.
Weaviate [Image Source]
4. Faiss
Faiss is an open-source library for the swift search of similarities and the clustering of dense vectors. It houses algorithms capable of searching within vector sets of varying sizes, even those that might exceed RAM capacity. Additionally, Faiss offers auxiliary code for assessment and adjusting parameters.
While it’s primarily coded in C++, it fully supports Python/NumPy integration. Some of its key algorithms are also available for GPU execution. The primary development of Faiss is undertaken by the Fundamental AI Research group at Meta.
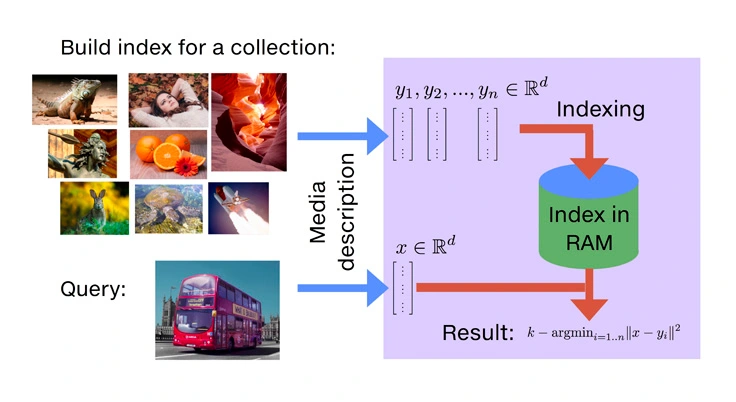
Faiss is an open-source library for vector search created by Facebook [Image Source]
5. Qdrant
Qdrant is a vector database and a tool for conducting vector similarity searches. It operates as an API service, enabling searches for the closest high-dimensional vectors. Using Qdrant, you can transform embeddings or neural network encoders into comprehensive applications for tasks like matching, searching, making recommendations, and much more. Here are some key features of Qdrant:
- Versatile API. Offers OpenAPI v3 specs and ready-made clients for various languages.
- Speed and precision. Uses a custom HNSW algorithm for rapid and accurate searches.
- Advanced filtering. Allows results filtering based on associated vector payloads.
- Diverse data types. Supports string matching, numerical ranges, geo-locations, and more.
- Scalability. Cloud-native design with horizontal scaling capabilities.
- Efficiency. Built-in Rust, optimizing resource use with dynamic query planning.
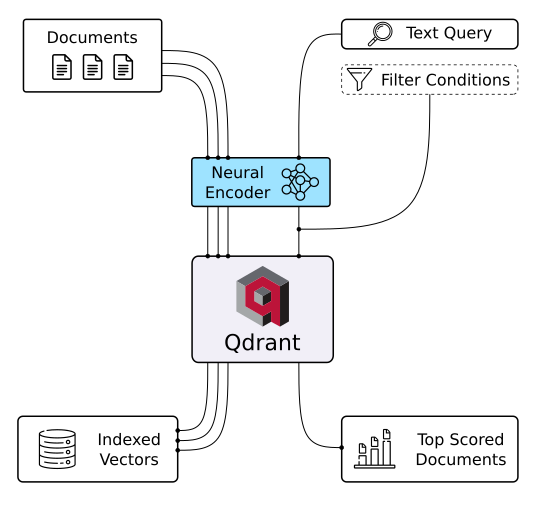
Qdrant[Image Source]


