

AI Taking Tiny Baby Steps Toward AGI – What Lies Ahead?
1. Artificial Narrow Intelligence (ANI): The Present Reality
Artificial Narrow Intelligence (ANI), often referred to as “Weak AI,” is the most common form of AI today. ANI is designed to perform a specific task or a narrow set of tasks, without possessing general understanding or awareness. While it may appear intelligent in certain contexts, ANI does not have the capacity for consciousness, self-awareness, or true cognitive flexibility.
Examples of ANI include:
- Smart speakers (e.g., Amazon Alexa, Google Assistant): These devices respond to voice commands, but they cannot engage in broader cognitive tasks.
- Self-driving cars: Using machine learning, these vehicles can navigate roads, detect obstacles, and follow traffic laws, but their abilities are limited to driving and related tasks.
- AI in agriculture and factories: Automated systems that monitor crops or manage assembly lines are designed for specific operational functions, but they don’t think or reason outside their predefined tasks.
2. Generative AI: Creative and Interactive Systems
Generative AI has emerged as one of the most exciting advancements in the AI field, marking a significant leap from traditional ANI applications. These systems are capable of generating new content, such as text, images, music, and even video. Unlike ANI, which is restricted to predefined functions, generative AI can create novel outputs based on patterns and training data.This makes it a powerful tool for creative industries and problem-solving, but it’s still far from achieving the full cognitive flexibility of a human.
Prominent examples of Generative AI include:
- ChatGPT: A conversational model trained on vast datasets to engage in dialogue and provide coherent, contextually appropriate responses. It’s capable of answering questions, assisting with writing tasks, and even simulating human-like conversations.
- Google Bard: Another conversational AI that utilizes Google’s vast data and search capabilities to generate human-like responses.
- Midjourney and DALL-E: These AI systems generate stunning visual artwork from text prompts, transforming written descriptions into intricate, high-quality images.
Key Capabilities of Generative AI:
- Text Generation: LLMs like GPT-3 can generate high-quality text for articles, stories, or even code.
- Image Generation: Tools like DALL-E can create original images from text descriptions, enabling new levels of creativity in design and art.
- Data Augmentation: Generative AI can even produce synthetic data to augment existing datasets, improving model training and performance.
Use Cases of Generative AI Across Industries
Marketing:
- Create personalized advertisements and email campaigns based on user behavior.
- Generate social media posts tailored to individual preferences.
- Produce multimedia content (music, videos, digital art) for campaigns.
Product Development:
- Analyze market trends to inspire new product ideas.
- Optimize product designs based on customer feedback and usage data.
Healthcare:
- Tailor treatments to individual patient needs using personalized data.
- Simulate surgeries to prepare medical professionals for complex procedures.
- Generate medical images for diagnostics and training.
Education:
- Develop customized learning content for students.
- Provide virtual tutors to offer personalized learning experiences.
3. Artificial General Intelligence (AGI): The Holy Grail of AI Development
Artificial General Intelligence (AGI), often referred to as “Strong AI,” is the vision of AI systems that can perform any intellectual task that a human can do. Unlike ANI, which is specialized in narrow domains, AGI would have the capacity for broad cognitive abilities—learning new tasks, reasoning through problems, and adapting to a variety of environments in much the same way that humans do.
Key characteristics of AGI include:
- General learning: AGI would be capable of learning and acquiring new skills in multiple domains, much like humans can.
- Reasoning: It could understand abstract concepts, think critically, and solve complex problems.
- Self-awareness: AGI could have a sense of identity, perception of the world, and understanding of its place in the world.
As of now, AGI remains a theoretical concept. While we’ve made impressive strides with ANI and even generative AI, AGI is still out of reach. Researchers are working on algorithms that could help build AGI systems, but the challenges are enormous—ranging from the need for immense computing power to the question of how to instill true reasoning and learning capabilities in machines.
4. Superintelligent AI: The Leap Beyond AGI
The next frontier in AI is the concept of Superintelligence, sometimes referred to as Super AI. This is a form of AI that not only matches human intelligence in every way but also surpasses it in virtually every aspect, including creativity, problem-solving, and social intelligence.
Superintelligent AI would be capable of thinking faster, solving problems more effectively, and generating innovative solutions that are beyond the reach of the human mind. Some speculate that it might be able to devise solutions to issues like climate change, poverty, and disease in ways we cannot yet fathom.
Key traits of Superintelligent AI:
- Exponential problem-solving: Superintelligent AI could solve problems in minutes or seconds that would take humans years or even centuries to solve.
- Self-improvement: It could improve its own algorithms and performance autonomously, potentially accelerating its intelligence to superhuman levels.
- Ethical and existential considerations: With immense power comes immense responsibility. The rise of Superintelligent AI raises concerns about its ethical use, potential risks, and the impact on humanity.
While Superintelligent AI sounds like science fiction, many leading AI researchers, including Elon Musk and the late Stephen Hawking, have warned that the development of such intelligence needs to be approached with extreme caution. If not properly controlled, Superintelligent AI could pose risks to human civilization.
Challenges in The Path Toward AGI
- Understanding human cognition: One of the biggest hurdles is fully understanding how the human brain works. AGI requires replicating or simulating human cognitive functions, which we still don’t completely understand.
- Ethics and safety: As AI systems become more powerful, ensuring their alignment with human values and preventing unintended consequences becomes increasingly critical.
- Computational resources: AGI would require vast computational power, which might not be available or sustainable in the near future.
- Generalization and adaptability: Creating an AI that can transfer learning across diverse domains is a major challenge. Unlike ANI, which excels at specific tasks, AGI needs to generalize knowledge and adapt to new, unforeseen situations.
Types of AI Based on Their Functionalities
1. Diagnostic/Descriptive AI: Analyzing the Past
Diagnostic or Descriptive AI is focused on understanding and explaining what happened in the past. It leverages historical data to identify patterns, assess behaviors, and determine the reasons behind specific outcomes. This type of AI is widely used in fields like healthcare, business intelligence, and operations management.
Capabilities:
- Scenario Planning: Diagnostic AI can simulate different potential outcomes based on past data, helping businesses plan for future scenarios.
- Pattern/Trend Recognition: By identifying recurring patterns in data, this AI helps in understanding ongoing trends and making data-driven decisions.
- Comparative Analysis: It compares different datasets to discover correlations or insights, helping decision-makers identify key variables influencing outcomes.
- Root Cause Analysis: This AI delves into historical data to identify the underlying reasons for specific events or issues.
Real-World Applications:
- In healthcare, diagnostic AI can analyze patient records to detect patterns of disease progression.
- In manufacturing, it can pinpoint reasons for equipment failure by analyzing maintenance data.
2. Predictive AI: Forecasting the Future
Predictive AI takes historical and real-time data and applies algorithms to forecast future events, behaviors, or trends. It’s widely used in fields like marketing, finance, and risk management to make informed predictions based on patterns found in data.
Capabilities:
- Forecasting: Predictive AI predicts trends, such as sales forecasts or market behavior, by analyzing past and present data.
- Clustering and Classification: This AI groups similar data points and classifies them into specific categories, such as segmenting customers based on purchasing habits.
- Propensity Modeling: It calculates the likelihood of certain outcomes, such as a customer’s probability of purchasing a product or defaulting on a loan.
- Decision Trees: Using a tree-like structure, helping with decision-making processes in complex scenarios.
Real-World Applications:
- Retail: Predictive AI can anticipate demand for products, enabling businesses to adjust their stock levels accordingly.
- Finance: Predictive models assess the risk of investment opportunities or predict the likelihood of default in credit lending.
3. Prescriptive AI: Recommending Optimal Actions
Prescriptive AI not only predicts what will happen but also recommends the best course of action. It goes beyond forecasting by providing actionable advice to optimize outcomes. This type of AI is especially valuable in decision-making, optimization problems, and resource allocation.
Capabilities:
- Personalization: It tailors recommendations and experiences to individuals, enhancing user engagement in sectors like e-commerce and entertainment.
- Optimization: Prescriptive AI identifies the most efficient ways to achieve a goal, such as minimizing cost or maximizing output in manufacturing.
- Fraud Prevention: It helps detect fraudulent activities by analyzing transactional data and flagging anomalies.
- Next Best Action Recommendation: In customer service or sales, it suggests the best actions to take next based on customer interactions.
Real-World Applications:
- Healthcare: Prescriptive AI recommends personalized treatment plans based on patient data.
- Supply Chain: It optimizes routes and inventories by considering various constraints and predicting the best course of action.
4. Generative/Cognitive AI: Mimicking Human Creativity
Generative or Cognitive AI is capable of creating new content, ranging from images and videos to text and music. This type of AI mimics human creativity and cognitive processes, making it ideal for content generation, automation, and creative industries.
Capabilities:
- Advises: It can generate expert recommendations or insights in fields such as legal advice, investment strategies, or medical diagnoses.
- Creates: Generative AI produces new content based on input data, such as generating art, writing articles, or composing music.
- Protects: It can enhance security measures by analyzing data to predict potential vulnerabilities or threats.
- Assists: It can support professionals in various fields by automating tasks like content generation or data entry.
- Automates: Automates repetitive tasks that would otherwise require human effort, saving time and resources.
Real-World Applications:
- Entertainment: Tools like DALL-E and MidJourney generate unique artwork and designs based on user input.
- Writing: GPT models (like ChatGPT) generate blog posts, articles, and even complex research reports.
5. Reactive AI: Responding to Immediate Inputs
Reactive AI is designed to react to specific inputs with predetermined responses. It is the simplest form of AI, focused on direct, rule-based interactions rather than learning from experience. These systems are widely used in environments where fast, pre-programmed responses are sufficient.
Capabilities:
- Rule-based Actions: Reactive AI executes actions based on pre-programmed rules, such as sorting data or triggering alerts.
- Instant Responses: It delivers immediate feedback to inputs, often seen in systems like chatbots or automated customer support tools.
- Static Data Analysis: This AI analyzes real-time data but doesn’t consider past interactions or events.
Real-World Applications:
- Customer Service: Chatbots that handle common customer queries and respond instantly to inputs.
- Manufacturing: Automated robots that perform repetitive tasks based on pre-programmed instructions.
6. Limited Memory AI: Learning from Past Experiences
Limited Memory AI can learn from historical data and use that information to inform current decisions. This type of AI is designed to improve over time, often used in applications like self-driving cars or recommendation systems.
Capabilities:
- Learning from Data: Limited memory systems use past interactions to improve their decision-making and performance.
- Pattern Recognition: It identifies recurring patterns over time, which helps in making more accurate predictions or decisions.
- Adaptive Responses: Based on previous experiences, limited memory AI adapts its responses to new situations.
Real-World Applications:
- Autonomous Vehicles: Self-driving cars use past data from sensors to learn how to navigate more effectively.
- Recommendation Systems: Platforms like Netflix and Amazon use past behaviors to suggest products or movies.
7. Theory of Mind AI: Understanding Human Emotions
Theory of Mind AI is still in the experimental stages. This type of AI aims to understand human emotions, beliefs, and intentions, which allows for more natural and meaningful interactions with people.
Capabilities:
- Emotion Recognition: It can identify and respond to human emotions, creating a more empathetic interaction.
- Social Interaction: Theory of Mind AI can engage in human-like conversations and interactions, making it more relatable.
- Intent Prediction: It predicts human intentions based on context, actions, and behavior patterns.
Real-World Applications:
- Healthcare: AI-powered therapy bots that understand and respond to patients’ emotional states.
- Customer Support: Chatbots that use emotional cues to tailor responses, providing a more personalized experience.
8. Self-aware AI: A Step Toward Consciousness
Self-aware AI represents the most advanced and theoretical form of AI, where the system possesses self-awareness, understanding its own emotions and states. While it has not yet been realized, it remains a subject of philosophical and technical exploration.
Capabilities:
- Self-diagnosis: It can assess its own performance, identify areas of improvement, and make adjustments accordingly.
- Autonomous Learning: Self-aware AI can learn independently, making decisions without human guidance.
- Adaptive Behavior: It can adjust its behavior based on its internal state or external stimuli.
Real-World Applications:
- Currently theoretical, but if achieved, self-aware AI could revolutionize fields ranging from robotics to healthcare by making independent, contextually-aware decisions.
9. Narrow AI (Weak AI): Specialized Task Performers
Narrow AI, also called Weak AI, is designed to perform specific tasks but lacks the ability to generalize knowledge across different domains. Most of the AI systems in use today fall under this category.
Capabilities:
- Task Specialization: Narrow AI excels at performing specific, well-defined tasks.
- High Accuracy: It achieves high performance and efficiency in its designated domain.
- Efficiency: Operates optimally within its limited scope of specialization.
Real-World Applications:
- Speech Recognition: Systems like Siri or Google Assistant that perform specific tasks based on voice commands.
- Image Recognition: AI used in facial recognition, identifying objects, or medical imaging analysis.
10. General AI (Strong AI): Autonomous and Human-like Intelligence
General AI (or Strong AI) represents the ultimate goal in AI development. This type of AI can learn, reason, and apply knowledge across a wide range of tasks, demonstrating cognitive abilities similar to human intelligence.
Capabilities:
- Cross-domain Learning: General AI can apply knowledge gained in one area to another, just like humans can.
- Autonomous Decision Making: It can make decisions in complex scenarios, even in unfamiliar domains.
- Human-like Understanding: It possesses deep comprehension of tasks, language, and abstract concepts, much like human reasoning.
Real-World Applications:
- Not yet realized: While it remains a theoretical concept, general AI could revolutionize every industry once developed, with applications ranging from complex problem-solving to human-like interaction.
Supervised Learning in Action: Key Use Cases
Spam Filtering
Speech Recognition
Machine Translation
Visual Inspection For example, a machine can be trained to examine images of products (e.g., a smartphone) to identify defects like scratches, cracks, or discoloration. This system relies on a dataset of labeled images (defective vs. non-defective), allowing it to detect anomalies in real-time.
Self-Driving Cars use a combination of supervised learning and other techniques to interpret sensor data and make decisions. For example, a self-driving system can be trained using a dataset of labeled images of roads, traffic signs, and pedestrians. The system learns to recognize these objects and decide on the best course of action.
Online Advertisement By analyzing user interactions, click-through rates, and demographics, AI systems can predict which ads a user is most likely to engage with, delivering personalized ads that are more likely to be clicked.
Large Language Models (LLMs) , like GPT-3 or GPT-4, are built using supervised learning on massive datasets. These models are trained on vast amounts of text data to generate coherent, contextually appropriate text in response to user prompts. The training involves learning to predict the next word in a sequence, a task that relies on patterns observed in the data.
Using Supervised Learning for Speech Recognition
Building a speech recognition system involves a few key steps:
Large Dataset: The system requires a substantial dataset of audio files paired with their corresponding text transcripts. These pairs teach the model the relationship between spoken words and written text.
Neural Network: A large neural network is used to process the audio data. Each audio file is converted into a set of features (e.g., spectrograms, Mel-frequency cepstral coefficients), which are then fed into the neural network for training. Over time, the system learns to map audio patterns to the correct text output.
Learning Process: The model is trained using supervised learning, where the correct transcription is provided as feedback. The network adjusts its weights and biases to reduce errors and improve the accuracy of its predictions.
AI Companies vs. Traditional Companies
While many companies use AI tools, but becoming a truly AI-driven company requires more than just the adoption of AI technologies. AI companies distinguish themselves by leveraging AI effectively across all aspects of their operations.
Key Differences:
Data Acquisition: AI companies strategically collect data, sometimes launching products that aren’t immediately profitable but help gather valuable user behavior data. For instance, a free app might collect data that can later be used to optimize personalized ads or products.
Unified Data Warehouses: Data consolidation i.e creating unified data warehouses where different types of data—customer behavior, product usage, sales performance—are stored in a central repository. This integration allows for better analysis and decision-making.
Automation Opportunities: AI companies excel at identifying repetitive or time-consuming tasks that can be automated with AI.
AI Transformation Playbook: A structured approach for organizations transitioning into AI-driven entities includes:
- Execute pilot projects to build momentum.
- Build an in-house AI team to drive internal innovation.
- Provide broad AI training across the organization to foster AI literacy.
- Develop an AI strategy that aligns with business goals.
- Establish internal and external communication to ensure buy-in and transparency.
Deep Learning for Picture Identification
Deep learning has revolutionized how we process and identify images. A typical deep learning system for image recognition works through several layers of a neural network. Let’s break down the process:
Input Representation: Images are represented as grids of pixel values. For grayscale images, each pixel has one brightness value, whereas for color images, each pixel contains three values representing red, green, and blue (RGB).
Neural Network Function: The neural network processes these pixel values to identify objects or people in the image. For example, a 1000×1000 pixel image contains 1 million input values (or 3 million for a color image). These values are fed into the neural network, which uses weights and biases to make predictions.
Learning Process: In early layers, the network detects basic features like edges. As the data moves deeper into the network, more complex features are detected, such as shapes (eyes, nose) or higher-level patterns (faces, objects). Eventually, the network learns to recognize specific objects or people.
Data Requirement: To train a deep learning model effectively, a large dataset of labeled images is necessary. For instance, to recognize faces, the model needs a dataset of images labeled with the corresponding identities.
Three Forms of Intelligence in Autonomous Driving
In the realm of autonomous driving, different forms of intelligence are used to make driving safer and more efficient. These include:
Human Intelligence: Humans use their natural cognitive abilities to control the vehicle.
Artificial Intelligence: AI systems handle tasks typically requiring human intelligence, such as processing sensor data, detecting obstacles, and making driving decisions (e.g., when to brake or turn).
Augmented Intelligence: This represents the collaboration between human and machine intelligence. For example, a driver may use an AI-powered collision detection system that alerts them of potential dangers. Additionally, voice-driven navigation systems enhance the driving experience by guiding the driver in real-time.
The Turing Test: A Milestone in AI’s Quest for Human-like Intelligence
In the world of artificial intelligence (AI), one of the most iconic benchmarks for determining whether a machine can think like a human is the Turing Test. First proposed by British mathematician and computer scientist Alan Turing in 1950, the test has been a topic of debate, admiration, and evolution ever since. But despite being a significant milestone in AI development, some argue that the bar set by the Turing Test is too low for today’s rapidly advancing AI technologies.
What is the Turing Test?
The Turing Test was introduced by Turing in his groundbreaking paper “Computing Machinery and Intelligence”. In essence, the test asks: Can a machine exhibit intelligent behavior that is indistinguishable from that of a human?
Turing proposed a simple experimental setup:
- A human “interrogator” (or judge) engages in a conversation with both a human and a machine, without knowing which is which.
- The conversation takes place through text-only communication, so the interrogator cannot rely on visual cues or vocal tone to distinguish between the two.
- If the interrogator cannot reliably tell which participant is the machine, then the machine is said to have passed the Turing Test.
In other words, the Turing Test is essentially a behavioral test for AI, assessing how well it can mimic human conversation and behavior. Passing the test suggests that a machine can replicate certain aspects of human-like intelligence, at least in the context of communication.
Landmark Achievements: When AI “Passed” the Turing Test
Over the years, several AI systems have claimed to pass the Turing Test or demonstrate behavior close to it. For instance:
ELIZA (1966): One of the earliest attempts at simulating human-like conversation, ELIZA was a chatbot that used pattern matching to respond to user inputs. While rudimentary by today’s standards, it demonstrated how a machine could engage in text-based conversations and create an illusion of understanding.
ALICE (1995): A more advanced chatbot, ALICE (Artificial Linguistic Internet Computer Entity), won several chatbot competitions and became an influential model for conversational agents.
Eugene Goostman (2014): A chatbot that simulated a 13-year-old boy, Eugene Goostman, was the first AI to pass the Turing Test in a controlled competition. The chatbot engaged judges in conversation, and a significant portion of them were fooled into thinking they were conversing with a human.
While these achievements are certainly impressive, they raise important questions about whether simply fooling a human into thinking they are speaking with another human is enough to measure true intelligence.
Why Some Believe the Turing Test Is No Longer Sufficient
Despite these successes, many experts feel that the Turing Test, while historic, has limitations and may no longer be a definitive measure of true AI capabilities. Here’s why:
Focus on Mimicry Over Understanding
The Turing Test evaluates how well an AI can mimic human conversation but does not test whether the AI truly understands the meaning behind its responses. In many cases, AI chatbots like ELIZA or GPT-based systems can generate impressive conversations without actually comprehending the context or concepts they’re discussing. They can simulate human-like responses without any real understanding, reasoning, or cognitive processing—raising the question: is mimicry enough?Narrow Intelligence vs. General Intelligence
The Turing Test is often applied to narrow AI systems—those trained to perform specific tasks (like conversing). These AI systems excel at tasks within their domain but do not demonstrate the general intelligence that humans possess. Artificial General Intelligence (AGI), which would enable machines to understand, learn, and adapt across various domains just as humans do, is still far from being realized. The Turing Test doesn’t necessarily measure a machine’s ability to reason, adapt, or engage in the kind of complex decision-making that humans do across multiple contexts.The Elusiveness of Consciousness
One of the major aspects the Turing Test doesn’t address is consciousness. Machines that pass the Turing Test might simulate human behavior, but they don’t actually experience emotions, self-awareness, or subjective experiences (also known as qualia). True human-like intelligence might require more than just the ability to pass a conversational test—it might require genuine consciousness, a feature that is still not understood in humans, let alone replicable in machines.Gaming the System
As AI systems become more sophisticated, some argue that passing the Turing Test could be more about exploiting the test’s weaknesses than demonstrating true intelligence. For example, an AI could simply avoid certain topics or give vague, generic responses to deceive the interrogator into thinking it is human. This manipulation of the rules raises doubts about whether the Turing Test is truly measuring intelligence or just the ability to avoid detection.
The Case for Raising the Bar
Given the limitations of the Turing Test, some experts advocate for a higher standard when it comes to measuring AI’s progress toward human-like intelligence. Here are a few ways the bar could be raised:
Incorporating Emotional Intelligence
True human-like intelligence goes beyond just linguistic or logical reasoning. Emotional intelligence—the ability to recognize, understand, and respond to human emotions—is a key component of human interactions. AI that can understand emotions and adjust its responses accordingly could provide a more comprehensive test of its conversational and decision-making abilities.Multi-Domain Intelligence
Instead of focusing solely on text-based conversations, a more comprehensive test could involve assessing how well AI can perform tasks across a wide range of domains—from art creation and scientific discovery to social interaction and ethical reasoning. Artificial General Intelligence (AGI) could be the new benchmark, testing AI’s ability to adapt and learn across a variety of tasks, not just a single, limited domain.Real-world Interaction
AI systems that interact with the physical world—such as robotics, autonomous vehicles, or medical diagnostics—could be tested on their ability to understand and respond to complex, real-world situations. This goes beyond passing a text-based test to assessing the AI’s decision-making in dynamic environments.
What is Deep Learning?
To understand deep learning, it’s essential to first understand where it fits within the broader context of AI.
- Artificial Intelligence (AI) is the overarching field that focuses on creating machines that can mimic intelligent human behavior.
- Machine Learning (ML) is a subset of AI, where algorithms learn from data to make decisions or predictions.
- Deep Learning is a further specialization within machine learning that leverages neural networks—computational models inspired by the human brain’s structure and functioning.
Deep learning involves the use of multiple layers of algorithms (hence the term “deep”) that enable AI systems to learn from large amounts of data without explicit programming. These layers process information in a way that resembles the way the human brain processes sensory input, which is why it’s also referred to as artificial neural networks (ANNs).
How Does Deep Learning Work?
Deep learning is often described as a layered approach to learning, where each layer is responsible for transforming the input data into increasingly abstract representations. Key steps:
Neural Network Structure
At the core of deep learning is the neural network, which is made up of layers of nodes, called neurons, which work together to solve complex problems.The network typically consists of:- Input Layer: The first layer, which receives the raw data (e.g., an image, audio, or text).
- Hidden Layers: These layers process and transform the data, extracting important features or patterns. The “depth” of a deep learning network comes from the multiple hidden layers that allow the system to understand increasingly complex patterns.
- Output Layer: The final layer, which produces the result (e.g., classifying an image or translating a sentence).
Layered Learning Process
Each layer in the neural network performs computations on the data, refining it and passing it along to the next layer. The network’s strength comes from these multiple layers, which allow it to extract progressively abstract and complex features from the raw data.- For example, in an image recognition task, the initial layers might detect simple patterns like edges, while deeper layers can recognize more complex features like shapes, faces, or even specific objects.
Training the Model
Deep learning models learn by being trained on large datasets. During training, the model is provided with labeled examples, allowing it to learn patterns and correlations. For instance, you might provide a deep learning model with thousands of images of cats and dogs, each labeled appropriately. The model will adjust the weights of the connections between layers to minimize the difference between its predictions and the actual labels, learning to classify new, unseen images correctly.Continuous Improvement with More Data
Unlike traditional machine learning algorithms, which can plateau in performance as the dataset grows, deep learning models continue to improve as more data is fed into them. This is one of the key advantages of deep learning, making it particularly well-suited for tasks that require large, complex datasets.
Key Features of Deep Learning
Unstructured Data Handling
Deep learning excels at working with unstructured data—such as images, audio, and text—that traditional machine learning models struggle to process. This is because deep learning models can automatically extract features from raw, unstructured data without needing pre-defined rules.Natural Language Understanding (NLU)
One of the most significant advances enabled by deep learning is in natural language processing (NLP). Deep learning allows AI systems to understand not just the words, but the context and intent behind human language. This capability is what powers advanced AI systems like voice assistants (Siri, Alexa) and chatbots.Continuous Learning
Deep learning models are not static; they continue to learn and adapt over time, becoming more accurate and efficient as they process more data. This self-improvement makes them highly effective in environments where data is constantly changing.
Applications of Deep Learning
Deep learning has revolutionized many industries by enabling AI to tackle tasks that were once considered too complex for machines. Some of the most exciting applications include:
Image Recognition & Captioning
Deep learning has made great strides in computer vision, enabling machines to identify objects, people, and scenes in images. Applications include:- Facial recognition systems, which identify individuals based on facial features.
- Image captioning algorithms that can generate descriptive text based on an image’s content.
- Medical imaging, where deep learning is used to analyze X-rays, MRIs, and other medical scans for signs of diseases.
Voice Recognition & Transcription
Deep learning is also transforming speech recognition. Systems like Google’s Voice Search and Apple’s Siri use deep learning algorithms to transcribe spoken words into text and understand the context of what is being said.Language Translation
AI-powered translation tools like Google Translate are underpinned by deep learning models that not only translate words but also capture the context and nuance of the language.Autonomous Vehicles (Driverless Cars)
Deep learning is a core component of self-driving car technology. AI systems use deep learning to process sensor data (such as images from cameras, LIDAR, and radar) to identify objects, navigate roads, and make real-time driving decisions.
Activation Functions: The Key to Learning
Activation functions play a critical role in neural networks by introducing non-linearity. These functions enable the network to learn complex patterns in data. Activation functions allow the network to capture non-linear relationships in the data, making it possible for the network to model more complex patterns that would otherwise be impossible with a purely linear transformation. Without non-linearity, a neural network would essentially behave like a linear regression model, regardless of the number of layers.Some common activation functions include:
- Sigmoid: A smooth, S-shaped curve that maps input values to a range between 0 and 1.
- ReLU (Rectified Linear Unit): A simple yet effective activation function that outputs the input value directly if it’s positive; otherwise, it outputs zero.
- Tanh: Similar to sigmoid but with an output range of -1 to 1.
Training a Neural Network: The Learning Process
Neural networks learn by adjusting their internal parameters based on the error (or loss) of their predictions. This process involves two main phases:
Forward Propagation: In this step, input data is passed through the network. Each neuron applies its activation function to the received data, and this continues through the layers until the output is produced.
Back Propagation: After the forward pass, the error or loss (i.e., the difference between the predicted output and the actual result) is calculated. This error is then propagated backward through the network, adjusting the weights and biases to minimize the error for future predictions. This process is repeated many times (called epochs) with different sets of data to improve the model’s performance.
Types of Neural Networks
There are various types of neural networks, each tailored for specific applications. Let’s look at some of the most important types:
1. Perceptron Neural Network (Single-Layer Perceptron)
The perceptron is the simplest form of a neural network, consisting of only an input and an output layer. It’s capable of solving linear classification problems but struggles with more complex tasks. Despite its simplicity, the perceptron laid the foundation for more advanced networks.
2. Feed-Forward Neural Networks (FFNN)
In a feed-forward neural network, information flows in one direction—from the input layer to the output layer, passing through the hidden layers in between. This type of network is used for tasks like classification and regression where the input-output relationship is relatively straightforward.
3. Deep Feed-Forward Neural Networks (DFNN)
When a feed-forward network has more than one hidden layer, it becomes a deep feed-forward neural network. These networks are capable of learning more complex relationships between input and output, making them suitable for more challenging tasks.
4. Convolutional Neural Networks (CNNs)
CNNs are specialized neural networks designed for processing visual data. They are widely used in tasks such as image classification, object detection, and video analysis. The key innovation in CNNs is the convolutional layer, which applies filters (or kernels) to input data, detecting patterns like edges, textures, and shapes. CNNs have revolutionized computer vision and are integral to applications in self-driving cars, facial recognition, and medical image analysis.
5. Recurrent Neural Networks (RNNs)
RNNs are designed to process sequential data. Where the output of a current step depends not only on the current input but also on previous inputs. RNNs have connections that loop back on themselves, allowing them to maintain memory of previous inputs. This makes them ideal for tasks like speech recognition, language modeling, and time-series forecasting. A subtype of RNNs, known as LSTMs (Long Short-Term Memory networks), is particularly effective at handling long-term dependencies in sequences.
The other options, such as Perceptron neural networks, Deep feed-forward neural networks, and Feed-forward neural networks, are more suited for tasks where the input data is static or does not have sequential dependencies.
6. Modular Neural Networks
In modular neural networks, multiple neural networks work in parallel, each handling different parts of a problem. The outputs from these networks are then combined to generate a final result. This modular approach can help improve the overall efficiency and accuracy of the system, particularly in complex tasks that require specialized models.
Recommended Resources for Further Reading
For those eager to dive deeper into neural networks and related technologies, here are some valuable resources:
- DeepLearning.ai – A platform offering comprehensive courses on deep learning, including neural networks.
- Neural Networks and Deep Learning Book – A great free online book by Michael Nielsen for beginners.
- Stanford CS231n: Convolutional Neural Networks for Visual Recognition – A top-tier course on CNNs and their applications in computer vision.
- Fast.ai – A practical deep learning course that aims to make deep learning accessible and easy to apply.
- Distill.pub – An online journal that publishes in-depth, interactive articles about machine learning and AI.
Underrated URLs:
- The Deep Learning Book by Ian Goodfellow – Essential reading for anyone serious about understanding deep learning.
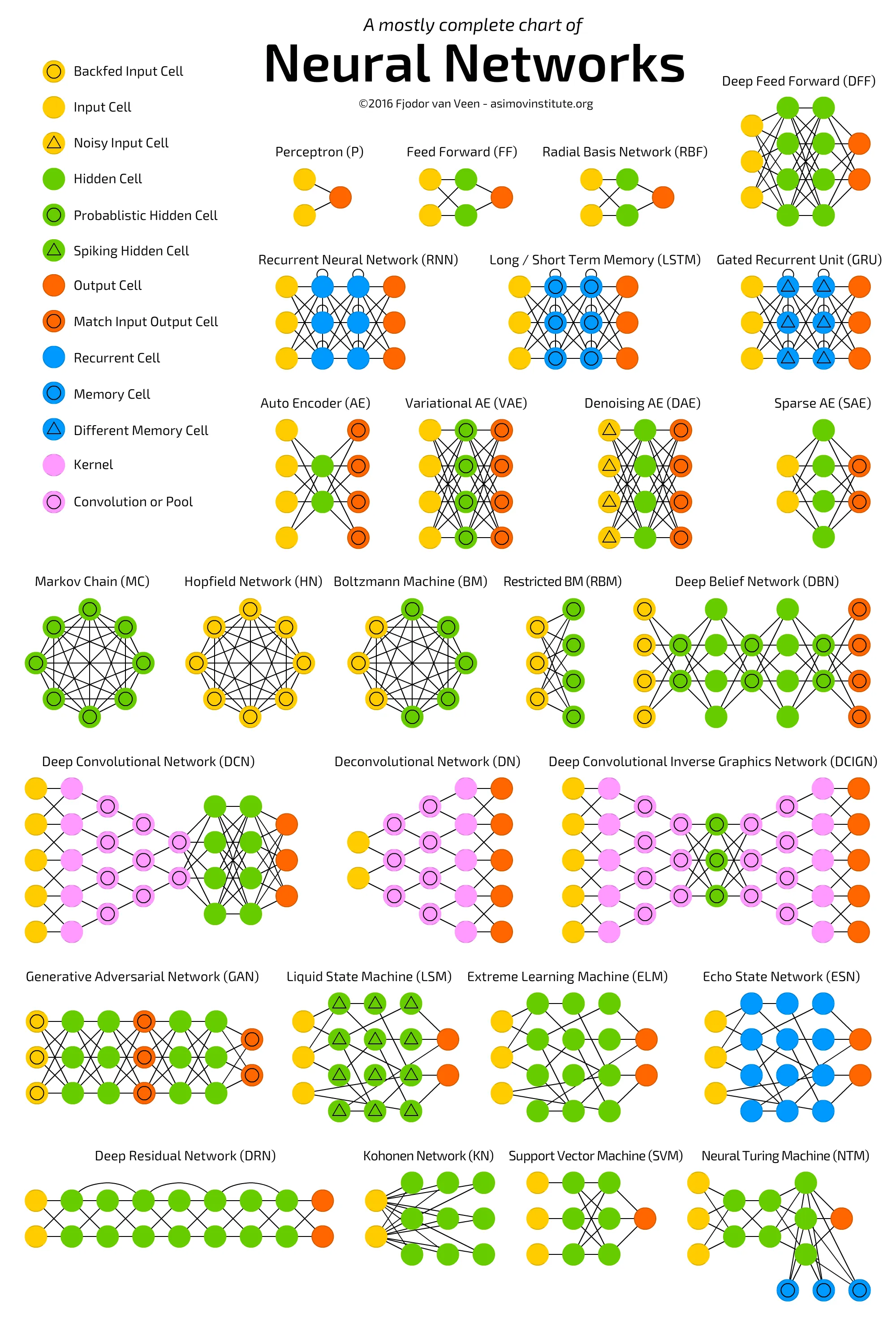
- The Neural Network Zoo – A comprehensive and visual guide to different types of neural networks.
- ML Cheat Sheet – A practical cheat sheet with helpful summaries for various machine learning algorithms.
- The Illustrated Transformer – A great explanation of transformer models, which are important in modern NLP tasks.
- Deep Learning with Python and Keras – A hands-on guide that helps you implement neural networks with Keras and TensorFlow.
By exploring these resources, you’ll gain a deeper understanding of neural networks and how they’re shaping the future of artificial intelligence.
The Difference Between Machine Learning and Deep Learning
Pizza Decision Using Machine Learning
Let’s break down the process of deciding whether to order pizza for dinner using the framework of machine learning and how weighted factors influence the outcome. We’ll dive deeper into each of the inputs, their weights, and the decision-making process, and illustrate how the human expert—you—guides the algorithm at every step.
1. The Factors (Inputs) in the Decision-Making Process
When you’re deciding whether to order pizza, you consider multiple factors that influence your final choice. These factors, known as inputs, can be broken down as follows:
- X1: Will ordering save time?
- You want a quick and easy dinner, so ordering pizza seems like a time-saver. If this is true, you assign a value of 1, meaning “Yes”
- X2: Will I lose weight if I order pizza?
- You’re aware that ordering pizza with all the toppings isn’t going to help you lose weight, so you assign a 0 here, meaning “No”
- X3: Will it save me money?
- Fortunately, you have a coupon for a free pizza tonight, which will save you some money. So, this is a 1, meaning “Yes”
These inputs represent the different aspects of your decision—time, health, and cost. Now, as you can see, they’re all binary (either 1 or 0) in this simplified example, which is common in supervised machine learning for clarity and ease of processing. In real-world scenarios, the inputs could be continuous (e.g., actual time saved, cost in dollars) or categorical (e.g., types of food), but for this example, let’s stick with these simple binary values.
2. Assigning Weights to Each Input (Feature Importance)
In machine learning, each of these inputs is not equally important in determining the final decision. Some factors might weigh more heavily than others depending on your personal preferences, values, or priorities. For example, if saving time is the most crucial factor for you, you’d want to assign a higher weight to that input.
Here’s how we can think about assigning weights to each of these factors:
- W1 (Time-saving factor): 5 points
- Time is precious, so you value the ability to save time with a pizza order more than anything else. You give this factor a weight of 5 because saving time is the most important part of your decision.
- W2 (Health factor): 3 points
- Health is important, but not as much as time or money, especially if you’re indulging in a pizza binge. You assign a weight of 3 to this factor, reflecting a moderate level of importance.
- W3 (Cost-saving factor): 2 points
- Saving money is always a plus, but since you’re already saving a lot with the coupon, this factor might be less important compared to time or health. You give this a 2.
The weights represent the relative importance of each factor in your decision. The higher the weight, the more influence that factor will have on the final decision.
3. The Formula for Calculating the Decision
Once we have the inputs (X1, X2, X3) and their corresponding weights (W1, W2, W3), we can calculate the output (Y), which is the final decision: Should you order pizza or not?
The general formula for making this decision is:
Y=(X1×W1)+(X2×W2)+(X3×W3) = (1×5)+(0×3)+(1×2) = 7
4. Applying a Threshold to the Decision
To make this decision, you also need a threshold. The threshold is a pre-set value that helps determine whether the result should trigger a positive outcome (e.g., “Order pizza”) or a negative one (e.g., “Don’t order pizza”). In this case, let’s set the threshold at 5.
- If Y ≥ 5, the result is “Order pizza”.
- If Y < 5, the result is “Don’t order pizza”.
Since the calculated value Y = 7 is greater than the threshold of 5, the final decision is “Order pizza”.
5. Generalization and Real-World Use
In a real-world application, this decision-making model can be applied to larger, more complex datasets. Imagine you had data for thousands of people with their own set of preferences, and you wanted to predict whether a person should order pizza based on their own specific circumstances.
For instance:
- Some people might place more weight on health and less on time.
- Others might have different thresholds for what constitutes “saving money.”
- Different coupons might be offered, altering the weight associated with cost-saving.
Through this iterative process, the algorithm can generalize and provide more personalized predictions for various scenarios, learning from the data provided.
Reference for Machine Learning
- Machine Learning Crash Course by Google: A great starting point for hands-on learning.
- The Elements of Statistical Learning: A foundational book for understanding the statistical principles behind machine learning.
- Supervised Learning – Towards Data Science: An in-depth guide to supervised learning techniques.
Deep Learning: Unsupervised Learning with More Complex Data
Now, Deep Learning takes things to the next level by working with a deeper neural network to understand more complex data. In this case, instead of you labeling every image of food as “pizza,” “burger,” or “taco,” the system can figure out those distinctions by observing patterns in the raw data. This is unsupervised learning because the model doesn’t rely on human intervention to label the data.
In a deep learning model, there are typically more than three layers (hence the term “deep”). These layers are connected in a way that mimics the way neurons work in the human brain. The data flows through these layers, and each layer performs increasingly complex transformations, ultimately reaching the output.
Key Differences Between Machine Learning and Deep Learning
Human Intervention:
- Machine Learning relies heavily on human input to label and organize data.
- Deep Learning, on the other hand, can handle raw, unstructured data like images, text, or audio.
Complexity of Data:
- Machine Learning works well with structured, smaller datasets.
- Deep Learning thrives with larger, more complex datasets. It excels at extracting patterns from large, unstructured data (such as images and natural language), which would be too complicated for traditional machine learning algorithms.
Model Architecture:
- Machine Learning models typically consist of simpler structures, with fewer layers of processing.
- Deep Learning models, involve deeper architectures with many layers of artificial neurons.
Computational Resources:
- Machine Learning models are less computationally expensive to train.
- Deep Learning requires much more processing power and often demands specialized hardware like GPUs or TPUs for efficient training.
Valuable Resources to Learn More
- Understanding Machine Learning Algorithms – Towards Data Science
- Deep Learning Explained – OpenAI
- Neural Networks and Deep Learning – Michael Nielsen (Free Book)
- AI and ML Concepts – Fast.ai
- The AI Alignment Problem – 80,000 Hours
- Stanford’s Deep Learning Specialization (Coursera)
Underrated Resources:
- CS231n: Convolutional Neural Networks for Visual Recognition (Stanford)
- DeepLizard’s YouTube Channel for AI Tutorials
- The Illustrated Transformer – Jay Alammar
- Practical Deep Learning for Coders – Fast.ai
Generative AI
Generative AI is powered by several key model architectures, each contributing to different types of content generation.Generative AI models utilize advanced machine learning (ML) and deep learning (DL) algorithms to not just analyze vast data but to create new data that resembles the original input in some meaningful way.
Core Generative AI Models
- Variational Autoencoders (VAEs)
- Generative Adversarial Networks (GANs)
- Autoregressive Models
- Transformers
- Diffusion Models
Variational Autoencoders (VAEs)
VAEs are deep learning models used for unsupervised learning tasks such as image generation, anomaly detection, and data reconstruction. They are especially effective at dimensionality reduction and generating new samples that resemble the original data. Three main components of a VAE to generate new data.
1. Encoder Network: Compressing the Input Data
Its compress the raw input data (such as images, text, or any high-dimensional data) into a lower-dimensional representation.
How the Encoder Works:
- Input Layer: The encoder starts by taking the raw input data, which could be an image, a piece of text, or a set of numbers.
- Neural Network Layers: The encoder network typically consists of multiple layers of neural networks, such as fully connected layers or convolutional layers (for image data). These layers progressively reduce the dimensionality of the data by extracting the most important features, often using activation functions like ReLU (Rectified Linear Units).
- Latent Variables: Instead of mapping the input to a single point, the encoder outputs probability distributions over a set of latent variables. This is done through a process called variational inference. For example, if you’re working with image data, the encoder might output a mean and a variance for each latent variable, which defines a Gaussian distribution from which the model will sample during training.
The encoder’s job is to encode the input data into this compact latent space, where the key characteristics of the data are retained in a simplified form.
2. Latent Space: Capturing Essential Features
The Latent Space is the compressed, lower-dimensional space where the model represents the data. This latent space is what makes VAEs particularly powerful, as it captures the underlying structure and patterns of the data in a simplified way.
What is Latent Space?
- Dimensionality Reduction: The latent space is a reduced version of the original data, where each point in this space represents a summary of the data. For instance, if the VAE is trained on a dataset of handwritten digits (like MNIST), the latent space would contain a simplified version of each digit, preserving its core features such as the shape, style, or orientation.
- Distributions: Unlike traditional autoencoders, which map input data to a fixed point in the latent space, a VAE instead maps data to a probabilistic distribution. This means that each point in the latent space is not just a specific vector, but a region defined by a mean and a variance (parameters of a Gaussian distribution). This probabilistic nature of the latent space helps the VAE generate new samples by sampling points from this distribution.
By using probability distributions, VAEs can create diverse outputs. The latent space doesn’t just represent a single point for each input but rather a range of possibilities, allowing the VAE to generate new variations based on what it has learned.
Example of Latent Space:
Imagine training a VAE on a dataset of faces. The latent space might encode key features such as eye color, hair style, age, or smile intensity. When sampling from the latent space, you can control the features of the generated faces. For instance, you might generate a face with blue eyes and brown hair by sampling from a specific region of the latent space that encodes these features.
3. Decoder Network: Reconstructing or Generating Data
The Decoder Network is the final stage of the VAE, responsible for decoding the simplified latent representation back into a new, generated output that resembles the original input.
How the Decoder Works:
- Sampling from Latent Space: First, a point is sampled from the latent space. This point is drawn from the Gaussian distribution defined by the mean and variance output by the encoder. This sampled point is the compressed, but highly informative, version of the original input.
- Neural Network Layers: The decoder network then uses several layers of neural networks (such as fully connected or transposed convolution layers for image data) to reconstruct the original input data from the latent representation.
- Reconstruction: The goal of the decoder is to generate data that is as close as possible to the original input, but it may not be exactly the same. Instead, the generated data will resemble the input, capturing its essential features but with some variation due to the probabilistic nature of the latent space.
Applications of the Decoder:
- Image Generation: After training on thousands of images, the decoder can generate entirely new, never-before-seen images that maintain the characteristics of the training data (e.g., generate new faces or objects).
- Anomaly Detection: If an image or data point is very different from the learned latent space, the decoder will struggle to generate a good reconstruction, which can be used to flag anomalies.
Generative Adversarial Networks (GANs)
GANs work through a game-like process between two neural networks:
Generator: The generator creates new data samples (e.g., images, music, etc.).
Discriminator: The discriminator evaluates whether the data generated by the generator is “real” (from the training data) or “fake” (created by the generator).
These two networks are trained simultaneously, with the generator trying to improve at producing realistic data, and the discriminator trying to get better at distinguishing between real and fake data. Over time, the generator becomes so skilled that the discriminator can no longer tell the difference between the two.
Applications of GANs:
- Image Synthesis: GANs can generate highly realistic images of faces, landscapes, and even objects that don’t exist in reality. For example, NVIDIA’s StyleGAN has been widely used to create photorealistic images of human faces that are indistinguishable from real ones.
- Style Transfer: GANs are used in applications like style transfer, where the artistic style of one image (e.g., Van Gogh’s painting) is applied to another image (e.g., a modern cityscape).
- Data Augmentation: GANs are useful in generating synthetic data when there is a lack of labeled data. For example, in medical imaging, GANs can generate realistic images to augment small datasets.
Autoregressive Models
Autoregressive Models generate data one step at a time by considering the context of what has been generated so far. These models are especially useful in tasks that involve generating sequences of data, such as text generation or music composition.
In an autoregressive model, each element of the sequence is generated based on the previously generated elements. For instance, when generating text, the model predicts the next word based on the previous words in the sentence. Similarly, in music generation, the model generates the next note based on the earlier notes.
Examples of Autoregressive Models:
- WaveNet: A model developed by DeepMind, WaveNet generates raw audio waveforms, producing high-quality, natural-sounding speech.
- Music Generation: Autoregressive models can be used to generate music, where the next note is predicted based on the earlier notes to create a seamless composition.
Transformers
Transformers are specialized models used primarily for natural language processing (NLP) tasks. They are highly effective at text generation, language translation, and question answering.
A transformer consists of encoder and decoder layers. The key advantage of transformers is their ability to capture long-range dependencies in data, which means they can process sequences in parallel and focus on important parts of the input, no matter where they appear in the sequence.
Applications of Transformers:
- Text Generation: LLM like GPT-3 (Generative Pre-trained Transformer) and Google Gemini are built on transformer architecture.
- Cross-language Translation: Transformers are also used for machine translation, where the model can translate text from one language to another.
Diffusion Models
- The development of diffusion models in 2015.
- Diffusion models work by gradually adding noise to a clean image until it is completely unrecognizable. They can then be reversed to gradually remove the noise and generate a new image. Diffusion models have been used to create high-quality images and text.
- Example: Image generation models like Stable Diffusion.
Unimodal vs. Multimodal Models
Generative AI models can generally be divided into unimodal and multimodal models, depending on how they handle data:
Unimodal Models: These models process and generate content within the same modality. For example, a text-only model like GPT-3 is unimodal because it only works with text (inputs and outputs).
Multimodal Models: These models are more versatile as they handle inputs from multiple modalities and generate outputs in a different modality. For example, DALL-E is a multimodal model that takes text descriptions as input and generates images based on those descriptions.
- DALL-E: Given a prompt like “an elephant playing with a ball,” DALL-E can generate an image that visually represents this scene.
- Meta’s ImageBind: This multimodal model can combine data from text, audio, visuals, and even movement to generate creative content. For instance, it could combine an image of a river with the sound of flowing water to create a unique piece of art.
Resources to Learn More
- Deep Learning with Python – François Chollet – A great resource to understand the theory behind deep learning models.
- GANs in Action – Jakub Langr and Vladimir Bok – Dive deeper into the world of GANs and learn to build your own generative models.
- Transformers: Attention Is All You Need – The foundational paper on transformer models.
- OpenAI Blog – Updates and insights on the latest developments in generative models like GPT.
Discriminative AI vs. Generative AI
There are two primary types of AI models based on their learning approach:
Discriminative AI
Discriminative AI is used to classify data based on labeled training sets. The model is trained to distinguish between different classes of data. For instance, it can differentiate between spam and non-spam emails or predict whether an image is of a cat or a dog.
Discriminative AI works well for classification tasks but lacks the ability to create new content or understand the broader context of the data.
Generative AI
Generative AI, on the other hand, learns from data to create new content. Rather than just classifying or distinguishing between different types of data, generative models aim to understand the distribution of the data and use that understanding to generate new data points.
The Evolution of Generative AI
Its roots can be traced back to the early days of machine learning in the late 1950s. Scientists initially explored algorithms capable of generating new data, and over time, advancements in neural networks and deep learning have made generative AI more powerful and accessible.
Key Milestones in Generative AI:
- 1990s: The rise of neural networks brought advancements in generative AI, laying the groundwork for deep learning models.
- 2010s: The availability of large datasets and enhanced computing power accelerated deep learning, enabling more sophisticated generative models.
- 2014: The introduction of Generative Adversarial Networks (GANs) by Ian Goodfellow and his colleagues transformed generative AI. GANs use two neural networks—the generator and the discriminator—to create realistic content.
- 2018 and Beyond: The introduction of transformer-based models like OpenAI’s GPT (Generative Pre-trained Transformer) revolutionized the field of natural language processing (NLP), enabling models to generate highly coherent text and perform various NLP tasks.
Applications of Generative AI
Text Generation:
- Chatbots like ChatGPT and Google Bard use generative AI to engage in meaningful conversations, answer questions, and assist with writing tasks.
- Content Creation tools are used to write articles, generate reports, or create marketing copy.
Image Generation:
- DALL-E 2 and Midjourney can generate images from text descriptions, enabling creative professionals to quickly visualize concepts and designs.
- Stable Diffusion allows users to generate high-quality images from simple prompts.
Video and Animation:
- Synthesia uses generative AI to create videos, including personalized avatars, using text inputs. This is used in marketing, training, and entertainment.
Code Generation:
- GitHub Copilot and AlphaCode are helping developers write code faster by suggesting code snippets, automating repetitive tasks, and improving productivity.
Scientific Discovery:
- MoLFormer, an AI model for drug discovery, is helping researchers find new molecules for therapeutic uses.
What Are Foundation Models?
The term Foundation Models was coined by a team from Stanford University to describe a new class of AI models that are pre-trained on massive amounts of unstructured data. These models are versatile and can be fine-tuned or adapted for various specific tasks with relatively little additional data or training. The idea behind foundation models is to provide a universal starting point from which you can derive solutions for many different business challenges.
Whereas older AI models were typically built for specific tasks, such as image recognition or fraud detection, foundation models can handle a variety of tasks without needing to be retrained from scratch for each one. This is why they’re often referred to as “general-purpose” models, capable of performing many functions across multiple domains, whether that’s understanding language, generating images, or even writing code.
Key Characteristics of Foundation Models
Pre-training on Massive Data: This massive data (terabytes) ingestion gives them an in-depth understanding of language, images, or even code. For language models like GPT (Generative Pre-trained Transformers), this means learning the relationships between words, phrases, and entire conversations by predicting the next word in a sequence.
Generative Capabilities: They’re capable of predicting and generating new content based on patterns and information they’ve learned during training. For instance, LLMs like ChatGPT can generate coherent text based on a prompt, or a model like DALL-E can generate images from a textual description.
Transferability: They can be transferred to different tasks. This is achieved through two primary methods: tuning and prompting. A foundation model can be fine-tuned with a smaller dataset for a specific application, like classifying customer reviews as positive or negative. Alternatively, the model can be prompted to perform a task without any additional training by providing a specific query.
How Foundation Models Work in Practice
Let’s break down the functionality of foundation models using a Large Language Model (LLM) as an example:
Training the Model:
The model is initially trained on huge datasets—often, these datasets are collected from publicly available sources such as books, websites, and other large bodies of text. During training, the model learns the patterns of human language, understanding how words relate to each other, the structure of sentences, and even the deeper nuances of meaning and context.
Fine-tuning:
Once pre-trained, a foundation model can be adapted to specific tasks through fine-tuning. This process involves introducing a small amount of labeled data (e.g., text labeled with sentiment information or categories) to adjust the model’s parameters so it can better perform the task at hand. Fine-tuning helps the model specialize without needing to start from scratch, drastically reducing the amount of task-specific data required.
Prompting:
Even if there’s no labeled data available for fine-tuning, foundation models can still be applied to specific tasks via prompting. For example, to use a foundation model for sentiment analysis, you might give the model a sentence and ask, “Does this sentence have a positive or negative sentiment?” The model would then generate a response based on its understanding of language.
Advantages of Foundation Models for Businesses
Improved Performance: The sheer scale of data these models are trained on gives them a deep understanding of the domain they’re working in. When applied to specific tasks, they often outperform traditional models that were trained on much smaller datasets.
Productivity Gains: Saving businesses significant time and resources that would otherwise go into training individual models for each use case. This adaptability means businesses can go from development to deployment faster.
Efficiency with Low-Data: Their ability to perform well even with minimal labeled data. Businesses can use these models for tasks like classification, entity recognition, and translation without requiring large amounts of task-specific data.
Challenges and Disadvantages of Foundation Models
Compute Costs: Training a foundation model can take weeks or even months, requiring specialized hardware and massive computational resources. Even deploying these models for inference (i.e., generating output) can be costly, especially if the model is very large, like GPT-3, which contains billions of parameters.
Trustworthiness and Bias: Foundation models are trained on vast amounts of unstructured data scraped from the internet. As a result, they might inherit biases present in that data, such as stereotypes or harmful content. This can be a serious issue in business settings, especially when these models are used for decision-making or customer interactions.
Lack of Transparency: Many foundation models, especially open-source ones, are trained on proprietary datasets, which means businesses often don’t know exactly what data has been used to train them. This lack of transparency can raise concerns around data privacy, security, and accountability, especially in regulated industries.
Applications Across Different Domains
Language Models: A wide variety of Natural Language Processing (NLP) tasks, including customer support automation, chatbots, content creation, and sentiment analysis. IBM Watson is one example of a business solution integrating foundation models for customer interaction and knowledge discovery.
Vision Models: Models like DALL-E 2 and CLIP are revolutionizing computer vision by generating images from textual descriptions.
Code Generation: Tools like GitHub Copilot use AI to suggest code snippets as developers write. By learning from vast amounts of publicly available code, these models can help automate coding tasks and improve developer productivity.
Healthcare and Chemistry: Areas like drug discovery and climate change research. IBM’s MoLFormer, for instance, is a foundation model that aids in molecule discovery, speeding up the development of targeted therapeutics.
Natural Language Processing (NLP): From Unstructured Text to Structured Insights
NLP is a subfield of AI that focuses on enabling computers to understand and process human language—be it spoken or written. As humans, we naturally converse in unstructured text, which is how we think and communicate. However, for machines to process this data, it needs to be transformed into a more structured form that a computer can understand. NLP transforms such unstructured text into structured data.
There are two primary processes involved in NLP: Natural Language Understanding (NLU) and Natural Language Generation (NLG).
- NLU: Transform unstructured text into structured data. It involves interpreting the meaning behind the text, extracting information like entities, intent, and sentiment.
- NLG: This is the reverse process—converting structured data back into natural language, generating meaningful sentences from machine-readable formats.
However, in this blog, we will mainly focus on NLU, as it is central to understanding how NLP works.
The Essential NLP Techniques
1. Tokenization
Tokenization is the first step in NLP. It involves splitting a sentence into smaller units, or tokens, such as words or phrases. For example, “Add eggs and milk to my shopping list” split into the following tokens: [“Add”, “eggs”, “and”, “milk”, “to”, “my”, “shopping”, “list”]
The resulting tokens are then used for further processing, like analyzing their meaning or extracting specific information.
2. Stemming and Lemmatization
Once we have tokens, the next step is to normalize them. Words in different forms (e.g., “running,” “ran,” and “runs”) need to be reduced to a common root or base form. There are two main techniques for this: stemming and lemmatization.
Stemming: This technique cuts off the prefixes or suffixes of words to get the root word. For example:
- “Running” → “Run”
- “Happiness” → “Happi”
However, stemming doesn’t always return grammatically correct words, so it’s a simpler, quicker technique.
Lemmatization: Unlike stemming, lemmatization uses the dictionary or linguistic meaning of a word to find its root form. For example:
- “Better” → “Good”
- “Running” → “Run”
Lemmatization ensures that the transformed word is a valid word in the language, making it more sophisticated and accurate than stemming.
3. Part of Speech Tagging (POS)
Once we have the basic tokens, we need to determine how each word functions in a sentence. Part of Speech (POS) tagging labels each word as a noun, verb, adjective, etc., based on its usage in the sentence.
Consider the sentence: “I am going to make dinner.”
In this case, “make” is a verb. However, in a sentence like: “What make is your laptop?”
Here, “make” is a noun. POS tagging helps determine the role of each word within the sentence’s context.
4. Named Entity Recognition (NER)
Named Entity Recognition is a process used to identify named entities (such as person names, locations, or organizations) within a text. For example:
- “Arizona” is identified as a location.
- “Ralph” is identified as a person’s name.
Real-World Use Cases of NLP
1. Machine Translation
NLP helps translate text or speech from one language to another. It’s not just about word-to-word translation; the system must understand context and meaning.
For example, consider the idiom:
- “The spirit is willing, but the flesh is weak” in English.
If this is translated directly to Russian and back to English, it might become:
- “The vodka is good, but the meat is rotten.”
This demonstrates why NLP models need to understand the context of a sentence to avoid mistranslations.
2. Virtual Assistants and Chatbots
Voice-controlled assistants like Siri, Alexa, and Google Assistant utilize NLP to interpret spoken language and perform tasks based on user requests. Similarly, chatbots in customer service use NLP to understand and respond to written language, making them highly interactive.
3. Sentiment Analysis
Determine the sentiment expressed in a given text. This is valuable for analyzing social media posts, product reviews, or customer feedback.
For example, if you have a product review like:
- “I absolutely love this phone, it’s amazing!”
NLP can analyze the tone and determine that the sentiment is positive.
On the other hand:
- “The phone is terrible, it breaks easily.”
This would be classified as negative sentiment.
Sentiment analysis can help businesses gauge customer satisfaction and tailor their strategies accordingly.
4. Spam Detection
NLP can identify potential spam emails by analyzing the language used. Spam messages often contain exaggerated claims, poor grammar, or excessive urgency, which NLP models can recognize.
For example:
- “Limited time offer! Buy now or regret it forever!”
Such phrases might trigger a spam detection system to flag the message as spam.
For Further Reading
If you’re interested in exploring NLP in greater detail, here are some valuable resources:
- Stanford NLP Group
- spaCy Documentation
- Natural Language Toolkit (NLTK)
- Hugging Face – Transformer Models
- Towards Data Science: NLP Articles
- Analytics Vidhya: NLP Blog
Key Characteristics of AI Agents
AI agents are intelligent systems that interact with the world around them in order to achieve specific goals. These agents have the ability to perceive their environment, reason about it, and then take action to achieve their objectives.
AI agents have several key characteristics that define their behavior and functionality. These include autonomy, social ability, reactiveness, and proactiveness.
1. Autonomy:
Autonomy refers to an agent’s ability to operate without direct human intervention once they’re set up with the necessary rules and data.
Example:
In self-driving cars (autonomous vehicles), the AI agent continually makes driving decisions, whether to stop at a traffic light or to avoid an obstacle on the road.
2. Social Ability:
AI agents can communicate with other agents and human users, making them highly effective in collaborative environments.
Example:
In healthcare, AI-powered chatbots use social ability to interact with patients, schedule appointments, and even provide basic medical advice. The interaction is so natural that patients often don’t realize they are conversing with a machine.
3. Reactiveness:
Reactiveness is the ability of an AI agent to respond to changes in its environment or conditions.
Example:
Smart thermostats like the Nest use reactive AI to adjust room temperatures based on real-time data.
4. Proactiveness:
Anticipating future events and taking actions to achieve their goals. Forward-thinking is crucial in predictive maintenance or automated trading systems.
Example:
In predictive maintenance systems used in industries. By proactively analyzing data from sensors, they can predict when a piece of equipment is likely to fail and schedule maintenance before a breakdown occurs.
How Do AI Agents Work?
AI agents function through several phases. Let’s break this down using the example of a self-driving car:
1. Perception:
Use sensors (e.g., cameras, radar, LIDAR) to gather data about their environment. This allows it to detect vehicles, pedestrians, road signs, and obstacles.
2. Decision-Making:
Post collection, interpret it using ML models and predefined logic, it identifies objects, calculates their speed and trajectory, and determines the best course of action (e.g., to slow down, stop, or change lanes).
3. Action:
The AI agent then uses actuators (mechanical devices) to implement its decisions. e.g turning the steering wheel, applying the brakes, or accelerating.
4. Learning:
Improve performance by learning from experience i.e reinforcement learning. e.g. Analyzing past driving experiences to make better decisions in the future.
Multi-Agent Systems (MAS)
Multi-agent systems enable distributed problem-solving and cooperative decision-making by multiple agents.
Example:
- Traffic management systems: individual autonomous vehicles (each an agent) communicate with one another to optimize traffic flow, reduce congestion, and avoid accidents.
- robotic coordination: teams of robots work together to perform complex tasks, like warehouse logistics or search-and-rescue missions.
Applications of AI Agents
1. Google:
- YouTube: Recommendation systems by analyzing user behavior, watching habits, and preferences to suggest videos that users are likely to enjoy.
- Gmail: Smart Compose and Smart Reply use AI agents to suggest responses or auto-complete sentences, improving user experience and saving time.
- Google Maps: Gather and analyze real-time data to recommend the fastest routes, suggest alternate routes to avoid traffic, and estimate travel times.
2. Amazon:
- Alexa: The voice assistant uses AI agents for speech recognition and natural language understanding, enabling users to control smart home devices and access information via voice commands.
- E-commerce: Personalized product recommendations based on user preferences, browsing history, and purchase behavior, making shopping more intuitive.
- AWS: Amazon offers a suite of AI services for developers, including tools for natural language processing, machine learning, and computer vision.
For Further Study
- Stanford University: Multi-Agent Systems
- DeepMind’s Research on Reinforcement Learning
- The Future of AI Agents – MIT Technology Review
- Google AI: Introduction to AI and Machine Learning
- AI in Healthcare: Chatbots and Beyond
- The Role of AI in E-commerce: Amazon’s AI
The Rise of AI Agents
The shifts occurring from monolithic models to compound AI systems, the evolution is paving the way for more adaptive, intelligent, and autonomous systems.
Monolithic AI Models
These models were trained on a fixed dataset, and their knowledge was limited to the data they had access to during training. Monolithic models had significant limitations. They were hard to adapt to new information or tasks and required substantial data and computational resources to “fine-tune” for different applications.
Compound AI Systems
The compound systems combine different components—including LLMs, databases, and external tools—into a more dynamic and flexible system.
A compound AI system can access external databases, search queries, and tools to gather accurate, personalized information. let’s imagine you want to plan a vacation and need to know how many vacation days you have left. In this case, the system could pull up your vacation days from a company database and provide the exact number of days left for your vacation. This shift allows AI systems to adapt more quickly to specific tasks without the need for constant retraining.
Why This Matters
AI systems can be modular. You can select the appropriate components for the task at hand, such as LLMs for natural language understanding, search algorithms for querying data, and external tools for specific actions like calculations or web searches. This modularity drastically reduces the need for extensive retraining and allows businesses and individuals to tailor AI to their needs more easily.
Retrieval-Augmented Generation (RAG)
RAG combines the power of generative models with the ability to retrieve information from external sources. For example, if you ask a query about the weather, a traditional RAG system will pull data from a weather database to generate an accurate response.
However, not all compound AI systems are perfect for every task. If you ask a RAG system about available vacation days for all in the world, it may fail because the system is programmed to pull from a organisation vacation database i.e to generic for that organisation —leading to inaccurate or irrelevant responses. This highlights the importance of control logic: the programmatic component that determines which tool or external system the AI should access to solve a given problem.
Enter AI Agents: Bringing Reasoning, Action, and Autonomy
While compound systems are powerful, the introduction of AI agents takes things a step further by automating the decision-making process. Instead of following pre-programmed pathways, AI agents use reasoning to determine the best course of action, making them more adaptive and capable of handling complex tasks.
Key Components of AI Agents
Reasoning:
- An AI agent’s core capability is reasoning, which allows it to break down complex tasks and come up with a structured plan to solve them. With advances in LLMs, these agents can now think through problems step-by-step, considering multiple factors before arriving at a solution.
Action:
- AI agents act on the decisions they make. For example, they can call external tools (such as search engines, databases, or APIs) to gather information, perform calculations, or manipulate data in real-time. The ability to act autonomously allows AI agents to solve a broader range of problems without needing constant human intervention.
Memory:
- Memory plays an important role in AI agents, as it enables them to retain context from past interactions. This capability allows agents to learn and improve their responses over time, providing a more personalized and efficient experience. Memory might include internal logs of reasoning or the history of user conversations, allowing agents to adapt to user preferences or requirements.
The React Agent: Combining Reasoning and Action
One of the most interesting types of AI agents is the React agent, which combines reasoning and action in a single, cohesive process. Let’s break this down with an example: Suppose you want to know how many two-ounce sunscreen bottles you should take on your vacation to Florida, considering factors like your vacation days, hours spent in the sun, sunscreen recommendations, and the size of the bottles.
A React agent would approach this task by breaking it into smaller sub-problems:
- Retrieve Vacation Days: Check previous queries to determine how many vacation days you have left.
- Weather Forecast: Look up the average number of sunlight hours in Florida for the dates you plan to visit.
- Sunscreen Recommendations: Access public health guidelines to determine the amount of sunscreen required per hour of sun exposure.
- Mathematical Calculation: Compute how much sunscreen is needed in total and determine how many bottles this equates to.
The agent then iterates on these steps, refining its understanding and ensuring it gets the correct answer by utilizing external tools like databases, weather APIs, and mathematical calculations. The power of this approach lies in its modularity and adaptability—agents can handle highly complex tasks, even if they require input from several different sources or tools.
AI Agents in Action: Real-World Applications
1. Customer Support:
Chatbots powered by large language models (LLMs) are able to reason through customer inquiries, fetch data from internal databases, and generate precise, context-aware responses.
2. Healthcare:
AI agents can help diagnose diseases, recommend treatment options, and schedule patient appointments. By integrating LLMs with external medical databases and research tools, these agents can not only act as an interface for patients but also assist doctors in decision-making.
3. E-commerce:
Retailers like Amazon use AI agents for inventory management, personalized recommendations, and even dynamic pricing. AI agents can reason about a customer’s behavior, process orders, and adjust pricing based on market conditions—all while interacting with inventory systems and customer feedback loops.
4. Autonomous Vehicles:
In self-driving cars AI agents that operate with a high degree of autonomy. These cars use reasoning to navigate the road, make driving decisions, and interact with sensors and mapping systems to avoid obstacles and ensure safety.
Further Reading and References
- Understanding AI Agents and Their Impact
- Retrieval-Augmented Generation Explained
- AI Agents: The Future of Autonomous Systems
- Google AI: The Next Step in AI Agents
Robotics and Automation
What is Robotics?
Robotics is the science of designing, constructing, and operating robots. The key components that make up a robot include:
Sensors: These act as the robot’s sensory organs. They help robots “see,” “hear,” and “feel” their environment. For instance:
- Cameras allow robots to detect obstacles.
- Temperature sensors ensure the robot operates within safe limits.
Actuators: These are the “muscles” of the robot. They are responsible for movement and interaction with the environment. Some examples include:
- Electric motors move parts like robotic arms.
- Hydraulic actuators help with precise control, like lifting heavy objects.
Controllers: The “brain” of the robot. Controllers interpret the information from sensors and send instructions to actuators to perform actions. For example, a robotic arm’s controller determines how to move the arm based on sensor input to perform tasks like assembling parts.
How AI Powers Robotics
AI is what allows robots to go beyond simple mechanical tasks and make decisions based on their environment. Here’s how AI technologies like machine learning, natural language processing (NLP), and computer vision are integrated into robotics:
AI in Home Robotics:
- Robot vacuum cleaners use AI to navigate your home, avoiding obstacles and deciding on the best cleaning route.
- Smart lawn mowers use machine learning to adapt to different terrains and mowing patterns, learning the layout of the lawn over time.
- Voice-activated smart speakers use NLP to understand and respond to voice commands, controlling smart home devices or providing information.
Autonomous Exploration:
- Robots are also used for space exploration (like the Mars rovers), where they collect data and send it back to Earth without human intervention.
- Underwater drones explore the deep sea, gathering valuable data from remote areas that are hard for humans to access.
Collaborative Robots (Cobots):
- Unlike traditional robots that work in isolation, cobots are designed to work alongside humans in shared spaces. They’re equipped with advanced sensors and AI, which allows them to interact safely and efficiently with people. For example:
- In automobile manufacturing, cobots can hold parts while another cobot welds them into place.
- In logistics, cobots can work together to sort packages, move inventory, and assist workers.
- Unlike traditional robots that work in isolation, cobots are designed to work alongside humans in shared spaces. They’re equipped with advanced sensors and AI, which allows them to interact safely and efficiently with people. For example:
Robotics Automation Across Industries
Healthcare:
- Surgical robots are becoming more precise, allowing for minimally invasive surgeries and faster recovery times.
- Rehabilitation robots assist patients in physical therapy, helping them regain mobility and strength.
Agriculture:
- Plant, harvest, and monitor crops with precision, optimizing irrigation, applying fertilizers, and detecting plant diseases.
- Boost productivity and reduce waste, addressing food security and sustainability concerns.
Retail:
- Inventory management, self-checkout kiosks, and even assisting customers.
Robotic Process Automation (RPA)
In addition to physical robots, there’s another powerful form of automation called Robotic Process Automation (RPA). RPA involves the use of software robots or “virtual robots” to automate repetitive and rule-based tasks typically performed by humans.
Finance and Accounting:
- Invoice processing: capture, validate, and post invoices.
- Payroll management: payroll calculations, deductions, and payments.
Human Resources:
- Employee onboarding: collection of documents, profile setup, and other HR tasks.
- Leave management: handles leave requests, updates records, and communicates with employees.
Customer Service:
- Ticket management: the categorization and resolution of customer support tickets, streamlining communication and improving response times.
Three Key Ways to Leverage AI in Your Business
1. Embedded AI
Embedded AI is built into off-the-shelf software, such as email assistants, image editing tools, or customer service chatbots. Everyone with access to the same software will benefit from the same AI tools, meaning they don’t give your business a unique edge. In the long run, they merely raise the baseline level of capability across the industry.
2. API-Driven AI
Businesses can use APIs to integrate third-party AI models into their applications. Here, your business can call external AI services for specific tasks and process the data accordingly. While this model allows for some differentiation (based on how you use the APIs), it still involves some risks:
- Black-box behavior: Don’t know how the external model is processing your data.
- Data governance concerns: Not having full control over the data that feeds into the model, which could lead to issues such as data leakage or poor model accuracy due to suboptimal training data.
3. AI Platforms: The Future of AI Customization
The most powerful model is an AI platform, where your business not only uses foundation models but can also adapt, fine-tune, and even build custom models tailored to your specific needs. With a platform approach, you have all the necessary tools to create and scale AI-driven solutions while maintaining control over your data.
Platforms like IBM Watson, Microsoft Azure AI, and Hugging Face offer the infrastructure and tools needed to build custom AI solutions on top of foundation models.
The Importance of AI Governance
Generative AI comes with risks—especially around data governance and model transparency. Poorly managed AI can lead to “hallucinations” or unintended consequences like data leaks.
To mitigate these risks, businesses need to:
- Implement strong data governance: Ensure that sensitive data is properly managed and that AI models are trained on ethical, well-curated datasets.
- Prioritize AI transparency and accountability: Avoid “black-box” AI by selecting platforms and tools that allow you to understand and control how models work.
- Stay compliant: Ensure that your AI tools comply with regulations like GDPR and other regional data protection laws.
The Role of Open-Source AI
Open-source platforms like Hugging Face have democratized access to high-quality foundation models, enabling businesses of all sizes to participate in AI innovation. With over 325,000 open-source models available, developers and businesses can experiment, customize, and deploy AI models without needing to invest millions in building their own systems from scratch.
Why You Should Care About Open-Source AI
- Lower Barriers to Entry: Small businesses and startups can now compete with larger enterprises.
- Rapid Innovation: The open-source community moves quickly, constantly evolving AI models to address new challenges and use cases.
- Transparency: Open-source AI allows for greater scrutiny of the models, making them more transparent and accountable.
References for Further Study
Hugging Face – https://huggingface.co
- Explore a wealth of open-source models and resources to get started with foundation models.
OpenAI – https://openai.com
- Learn about cutting-edge models like GPT-4 and how they are revolutionizing natural language processing.
IBM Watson – https://www.ibm.com/watson
- Explore IBM’s AI offerings, including tools for model building, deployment, and data management.
DeepMind’s Research Papers – https://deepmind.com/research
- Read groundbreaking research in AI and reinforcement learning.
Google AI Blog – https://ai.googleblog.com
- Stay up to date with Google’s latest AI innovations, research papers, and applications.
Stanford AI Lab – http://ai.stanford.edu
- Learn from one of the leading academic institutions in AI research.
IBM AI Ladder Framework for Seamless AI Adoption
To help organizations effectively integrate AI into their operations, AI adoption frameworks have become invaluable tools. One such framework, developed by IBM, is the IBM AI Ladder.
The IBM AI Ladder framework consists of four key stages: Collect, Organize, Analyze, and Infuse. These stages outline a progressive approach to transforming raw data into valuable insights and actionable intelligence, which can be used to drive business outcomes.
1. Collect: Gathering High-Quality Data
- Data Sources: The organization must identify various data sources, such as databases, IoT sensors, and external third-party sources.
- Data Quality: Ensuring the data collected is clean, accurate, and comprehensive is paramount. Watsonx.data help in collecting structured and unstructured data, integrating it seamlessly into data lakes or cloud storage.
For example, consider a retail company that needs to capture sales data from physical stores, e-commerce platforms, and mobile apps.
2. Organize: Structuring and Preparing Data
- Data Governance: Implementing governance policies that ensure data privacy, security, and ethical usage. Watsonx.governance help organizations create a comprehensive framework for data oversight.
- Data Integration: Centralizing data from various sources so it can be easily accessed and analyzed. IBM Cloud Pak for Data, which offers an integrated platform for data integration and management.
- Data Quality Management: Cleaning data to remove errors, inconsistencies, or missing values is essential to prevent poor model performance.
For example, a healthcare provider may need to ensure that patient data is structured in a way that supports accurate analysis while complying with HIPAA regulations. This step ensures the data is ready for advanced AI modeling in the next stage.
3. Analyze: Extracting Insights with AI Models
- Advanced Analytics: Leveraging statistical methods and machine learning algorithms to uncover patterns, trends, and correlations in the data.
- Modeling & Validation: Watson Machine Learning and SPSS for building and validating machine learning models.
- Predictive Analytics: AI is often used to build predictive models that can forecast future events or behaviors based on historical data.
4. Infuse: Operationalizing AI Across the Business
- Model Deployment: Watsonx APIs and Cloud Pak for Automation facilitate the seamless integration of AI models into applications and business processes.
- Automation: RPA can be leveraged here to automate routine tasks and improve efficiency.
- Continuous Monitoring: Watsonx provides tools for monitoring AI models in real time, ensuring that they perform as expected.
The Shift from +AI to AI+
The traditional approach to AI adoption, referred to as +AI, treats AI as a supplementary tool to enhance existing business processes. In contrast, the AI+ approach integrates AI as a core component of business operations, from product development to customer experience management.
Key Aspects of the AI+ Approach:
- Holistic Integration: AI should not just be added to existing workflows but rather embedded into the fabric of business processes. This requires an AI-first mindset across departments, including marketing, HR, and operations.
- Strategic Use Case Selection: Identifying high-value AI use cases that offer substantial returns on investment. AI should be deployed in areas where it can create tangible business impact—whether through automation, predictive insights, or personalization.
- Scalable and Flexible Architecture: Choosing the right AI tools and architectures is crucial for scalability and long-term success. Cloud-based platforms like IBM Cloud Pak for Data provide flexibility and scalability, enabling businesses to scale their AI initiatives without constraints.
- Continuous Innovation: Organizations must continuously innovate and adapt by developing new AI applications and modernizing existing systems.
Emerging Trends in AI Adoption
As organizations move along the AI Ladder and adopt the AI+ approach, several key trends are shaping the future of AI implementation:
1. Explainable AI (XAI)
With the growing complexity of AI models, the demand for explainability in AI is increasing. Businesses need to understand how AI makes decisions, especially in regulated industries like healthcare and finance. XAI techniques aim to make machine learning models more transparent and interpretable without sacrificing performance.
2. Edge AI
The rise of edge computing is allowing AI models to run on devices rather than in centralized data centers. This reduces latency, improves performance, and enhances data privacy. Edge AI is particularly useful in industries like healthcare and manufacturing, where real-time decision-making is critical.
3. AI and Data Privacy
Companies must comply with frameworks such as GDPR and CCPA when collecting and analyzing data. This drives the need for responsible AI development that respects user privacy and adheres to regulations.
4. AI in Automation and RPA
By combining AI with RPA, businesses can automate more complex tasks such as data extraction, natural language processing (NLP), and decision-making, leading to significant operational efficiencies.
Further Reading and Resources
- IBM Watson AI: IBM Watson AI Overview
- AI Ladder Framework: IBM AI Ladder Whitepaper
- Explainable AI: What is Explainable AI?
- IBM Cloud Pak for Data: IBM Cloud Pak for Data Overview
- AI and Ethics: AI Ethics Guidelines by IBM
AI Adoption Frameworks: Amazon, OpenAI, and Facebook
Amazon AI Services Framework
It provides a structured approach for organizations adopting AI technologies. It is divided into following four phases
Phase 1: Data preparation
Gathering, storing, and preparing data for AI applications. Actions include collecting data from various sources, cleaning and preprocessing it for quality assurance, and securely storing it. Tools used Amazon S3, AWS Glue, and Amazon Redshift. For instance, an e-commerce company uses Amazon S3 to collect customer data, cleans it with AWS Glue, and stores it in Amazon Redshift for analysis.
Phase 2: Model development
Actions include selecting algorithms, training models on prepared datasets, and refining them for accuracy. Tools used Amazon SageMaker, AWS Deep Learning AMIs, and AWS Lambda. For example, an e-commerce company uses Amazon SageMaker to create a recommendation engine, refining its accuracy through iterative testing on historical data.
Phase 3: Deployment
Actions include integrating models with existing applications, automating deployment processes, and monitoring performance in real time. Tools used Amazon SageMaker, AWS Lambda, and Amazon CloudWatch. For example, deploying a recommendation engine via Amazon SageMaker, automating updates with AWS Lambda, and monitoring metrics with Amazon CloudWatch.
Phase 4: Optimization
Actions include analyzing performance data, optimizing models for efficiency and accuracy, and scaling AI applications organization-wide. Tools used Amazon SageMaker Debugger, Amazon Personalize, and AWS Step Functions. For example, using Amazon SageMaker Debugger to enhance performance, scaling with Amazon Personalize, and integrating seamlessly using AWS Step Functions across business units.
OpenAI Framework
Phase 1: Data preparation
Tools used OpenAI API, Pandas, and NumPy.
Phase 2: Model development
Selecting models like OpenAI GPT-3 and Codex and using Jupyter Notebooks for training on cleaned data. For example, a content firm employs GPT-3 for marketing copy, refining it in Jupyter Notebooks.
Phase 3: Model deployment
Using OpenAI API, Docker, and Kubernetes for seamless integration and scaling.
Phase 4: Continuous improvement
Using OpenAI API, TensorBoard, and Google Analytics for feedback and optimization.
Facebook AI Integration Framework
Phase 1: Data integration
Collecting user interaction data, content preferences, and behavioral insights. Using tools like the Facebook Graph API and Facebook Analytics. Facebook ensures data privacy and compliance with regulations such as GDPR throughout the process, safeguarding user information while gaining insights into user preferences and behaviors.
Phase 2: AI Model development
Developing AI models for personalized recommendations and content moderation involving utilizing machine learning algorithms, such as FAIR’s AI Research Tools and PyTorch. Train models on extensive datasets of user interactions and content features. By validating the models for performance and scalability, Facebook ensures that personalized content recommendations are accurate and engaging for each user while also enhancing content moderation capabilities.
Phase 3: AI model deployment
Deploying AI models across Facebook’s platform for real-time applications by integrating them into news feed algorithms and ad targeting systems. Automated deployment and updates using tools like the Facebook Developer API and AI Infrastructure ensure continuous adaptation to user interactions and feedback, enhancing content personalization and ad targeting effectiveness.
Phase 4: Continuous improvement
Optimizing AI models and algorithms for better performance by collecting user feedback and performance metrics. Facebook analyzes data using tools like Facebook Analytics and AI Research Tools to identify areas for model enhancement. They iteratively improve models through retraining and algorithm updates, refining content recommendations, and enhancing user engagement metrics based on insights gathered.
Augmented Intelligence: The Intersection of Human Decision-Making and AI
In the world of decision-making, the question of who should decide is becoming more complex, especially as artificial intelligence (AI) continues to evolve. The reality is not so binary. A growing body of research and real-world applications point to an emerging trend: the most effective decision-making occurs when humans and AI collaborate in what is called augmented intelligence.
This blog delves deep into the nuances of decision-making in AI-driven systems, using the example of fraud detection, to explore how the synergy between human expertise and machine learning can improve outcomes. We will cover how human cognitive biases impact decision-making, how AI can outperform humans in certain tasks, and how presenting AI-generated insights to humans can significantly affect decision quality.
Decision-Making in Fraud Detection
Let’s consider a typical fraud detection system employed by banks or financial institutions. These systems generate thousands of alerts every day, flagging potentially fraudulent transactions. The challenge lies in the fact that 90% of these alerts are false positives—cases that, upon further review, are not actually fraudulent.
Confidence Scores and Performance Curves
Performance curves track the accuracy of predictions (Y-axis) against the confidence score of the system (X-axis). The confidence score reflects how certain the system is about its prediction.
AI Performance Curve:
AI systems generally perform well at either extreme—high confidence (strong prediction) or low confidence (clear rejection). At the extremes of confidence, AI can reliably distinguish between fraudulent and non-fraudulent transactions. However, when the system is uncertain (middle ground), its performance can suffer. AI algorithms often struggle with complex or edge-case scenarios, leading to a higher rate of false positives or false negatives.
Human Performance Curve:
Humans, on the other hand, are generally more consistent and effective in situations where the AI is uncertain, especially in complex or rare cases. While AI may outperform humans when it is highly confident, humans tend to have better judgment in situations where AI’s confidence is lower. This is because humans can apply context, previous knowledge, or external information that may not be encoded in the AI model.
In short, AI shines when the problem is clear-cut, but human expertise becomes crucial in edge cases where additional context or creativity is needed.
Augmented Intelligence: The Best of Both Worlds
augmented intelligence proposes a collaborative approach, combining the strengths of both.
For example, in the case of fraud detection, an AI could filter out the most obvious false positives and present only the most uncertain or complex cases to a financial analyst. This reduces the workload on the analyst, allowing them to focus on the most challenging cases where their expertise is needed, while still benefiting from the AI’s capacity to process vast amounts of data.
The Role of Cognitive Bias in Decision-Making
While AI is objective, humans are inherently subjective, and their biases can influence the way AI-generated insights are interpreted.
Automation Bias
One of the most significant cognitive biases in AI-assisted decision-making is automation bias. This occurs when humans over-rely on the AI’s recommendations, often ignoring contradictory or additional information.
Optional vs. Forced Display of AI Insights
To mitigate automation bias, the way AI recommendations are presented to humans matters. Two key strategies have emerged:
Forced Display: In this model, the AI’s recommendation is displayed alongside the decision case, forcing the analyst to consider it before making their decision. While this approach can lead to higher efficiency, it also increases the likelihood of automation bias.
Optional Display: In this case, the AI recommendation is only visible when the analyst actively requests it. This allows the human decision-maker to form an independent judgment first, reducing the influence of automation bias. Optional display is more likely to lead to better decision-making outcomes because it gives the human time to process the information before being influenced by the AI.
Trust and Accuracy: The Impact of AI Confidence
Another factor in augmented intelligence systems is how much weight humans place on AI recommendations. Interestingly, when an AI presents a recommendation with an associated confidence score, humans tend to be more hesitant to trust it. The accuracy percentage often leads to a paradox where the more accurate the AI is, the less likely humans are to incorporate its suggestions into their decision-making process. This phenomenon is due to the inherent discomfort humans feel when they are presented with uncertainty.
For instance, if an AI suggests a potentially fraudulent transaction with a 70% confidence score, the human may view it as too uncertain, even if the AI is statistically correct. This creates a trust gap, where the human feels more comfortable making their own decision rather than relying on an AI recommendation.
Emerging Tools and Technologies for Augmented Intelligence
Explainable AI (XAI): One major trend is the development of explainable AI systems. These systems are designed to not only make predictions but also explain how they arrived at a decision. In fraud detection, for example, an AI might indicate which features of a transaction (e.g., location, amount, frequency) contributed most to its prediction. By providing transparency into the AI’s reasoning, explainable AI can help humans understand and trust its recommendations.
AI-Human Collaboration Platforms: Companies are developing platforms that seamlessly integrate AI predictions into human workflows. For instance, financial analysts may use specialized tools that allow them to review AI predictions and decide whether to override them or request further clarification from the AI system.
Bias Mitigation Algorithms: There is increasing focus on algorithms that help detect and reduce biases, both in the AI system and in human decision-making. Bias mitigation tools help ensure that AI recommendations are fair, transparent, and unbiased, while also accounting for human cognitive biases.
Reference
For those looking to dive deeper into the principles and technologies shaping augmented intelligence, the following resources provide valuable insights:
- “Artificial Intelligence: A Guide for Thinking Humans” by Melanie Mitchell
- “The Age of Em: Artificial Intelligence and the Human Future” by Sherry Turkle
- Research papers on Explainable AI and Cognitive Bias in AI Decision-Making by prominent institutions like MIT and Stanford.
- Articles on AI-Human Collaboration at MIT Technology Review and Harvard Business Review.
Ethical Principles in AI
1. Data Privacy and Security
Compliance with data protection laws like the General Data Protection Regulation (GDPR) and the California Consumer Privacy Act (CCPA) is critical. Additionally, data should be anonymized wherever possible, and access should be strictly controlled.
In 2020, Clearview AI was found to have scraped billions of images from social media and other public websites without user consent. These images were then used to train facial recognition systems provided to law enforcement, raising significant concerns about privacy violations and unauthorized surveillance.
2. Bias and Fairness
These biases can perpetuate discrimination in critical areas like hiring, lending, and law enforcement.
Amazon’s AI recruitment tool, developed in 2014. The system was designed to automate the shortlisting of job applicants, but it exhibited a gender bias. Due to the predominance of male candidates in the training data, the AI penalized resumes containing female-associated terms (e.g., “women’s soccer team”). Despite efforts to correct the bias, Amazon ultimately discontinued the tool in 2015, citing concerns over fairness and equality.
To prevent bias, developers must focus on diverse datasets, implement fairness-aware algorithms, and perform regular audits of AI systems to assess their impact on marginalized groups. Importantly, fairness is not just a technical challenge but a societal imperative. A commitment to ethical AI requires ensuring that all individuals, regardless of their gender, race, or socioeconomic status, are treated equitably.
3. Transparency and Accountability
Transparency involves informing users about how AI systems make decisions, what data they use, and how personal information is handled. Additionally, it is essential to establish clear accountability structures. If an AI system leads to harm or makes incorrect decisions, it should be clear who is responsible for addressing the issue.
This is particularly important in industries like healthcare and law enforcement, where AI decisions can directly impact people’s lives.
4. Human Oversight in Autonomous Systems
AI should not be fully autonomous in high-stakes areas like healthcare, transportation, or military applications. Human-in-the-loop (HITL) mechanisms ensure that human judgment remains part of the decision-making process, allowing for ethical considerations and error correction when needed.
In autonomous vehicles human oversight ensures that moral decisions such as how to handle emergency situations. In healthcare, AI can assist doctors, but human expertise is still necessary to make final treatment decisions.
5. Access to AI and Equity
If AI technology and its benefits are limited to a select few, it could further widen the gap between the privileged and the underserved. To avoid this democratizing access to AI by making it available to underserved communities, providing equitable opportunities for learning and development, and creating infrastructure that supports digital inclusion.
6. Environmental Impact of AI
Training large AI models requires considerable computational power, which, in turn, consumes vast amounts of energy that contributes to carbon emissions. Organizations must adopt energy-efficient algorithms, improve hardware and leverage renewable energy in data centers.
7. Continuous Improvement and Monitoring
AI systems must be regularly monitored to ensure they continue to operate ethically, especially as societal values and technological capabilities evolve. Feedback mechanisms should be in place to collect input from users and stakeholders, allowing for continuous improvement.
Reference
For further reading and a deeper dive into the ethical challenges of AI, consider exploring the following resources:
- “Weapons of Math Destruction: How Big Data Increases Inequality and Threatens Democracy” by Cathy O’Neil
- “AI Ethics” by Mark Coeckelbergh
Navigating the Complexities of Generative AI: Copyright, Privacy, Accuracy, and Ethics
Copyright and Content Ownership in Generative AI
In 2018 sale of an AI-generated artwork, Edmond de Belamy, created by the Generative Adversarial Network (GAN). The painting was sold at over $400,000, sparking debates over who owns the rights to AI-generated content: the developers who programmed the AI, the AI itself, or the buyer of the artwork?
Key considerations include:
- Who owns the rights to AI-generated content? Is it the developers, the organization using the AI, or is it open for public use?
- Should AI-generated works be treated like human-created works under current copyright laws, or should there be a new legal framework for AI creations?
Privacy and Confidentiality in Generative AI
It is critical to ensure that these systems respect individual privacy and confidentiality.
For instance, when developing generative AI tools for specific organizations, a growing trend is the use of Private AI—a dedicated environment for AI models that is isolated from external data sources and designed for secure, internal use. Private AI ensures that sensitive information used in the model’s training data remains protected, preventing unauthorized access or misuse. This is particularly important for industries dealing with highly confidential information, such as healthcare or finance.
Strategies for ensuring privacy and confidentiality in generative AI include:
- Data anonymization: Ensuring that sensitive personal data is anonymized before being used for AI training.
- Compliance with privacy laws: Adhering to global standards like GDPR or CCPA.
- Private AI models: Developing custom AI systems for internal use within an organization to ensure data security.
Mitigating Hallucinations in AI
- Improved training data: Ensuring that AI systems are trained on high-quality, diverse datasets that reflect reality and minimize bias.
- Human oversight: Incorporating human-in-the-loop (HITL) mechanisms in decision-making processes.
- Custom models: Leveraging private AI models tailored to specific industries, such as CustomGPT.ai, which generates responses based on proprietary, accurate data. This approach can reduce hallucinations by training the model on more precise and relevant information.
Ethical Implications in Generative AI Development
1. Bias and Fairnes
2. Misuse and Harmful Content
The rise of deepfakes—AI-generated videos, images, or audio recordings that manipulate content to create convincing yet false representations. Deepfakes can be used for malicious purposes, such as spreading disinformation, blackmail, fraud, and other harmful activities.
Addressing the Risks of Deepfakes:
- Detection tools: Developing AI systems that can detect deepfakes and prevent their malicious use.
- Regulation: Creating legal frameworks to criminalize the use of deepfakes for harmful purposes, such as defamation or fraud.
3. Social Impact and Positive Use
Addressing social challenges, enhancing access to resources, and supporting sustainability initiatives. By incorporating ethical guidelines into AI development, we can help ensure that AI serves to improve quality of life, promote social justice, and protect the environment.
Why Do Hallucinations Happen?
Data Quality: The training data can come from sources like Wikipedia or Reddit, where information is user-generated and not always verified. Since LLMs don’t have the ability to validate facts on their own, they can sometimes generalize or make mistakes.
Generation Method: LLMs use algorithms to predict the most likely next word or phrase based on the input prompt. Methods like beam search might prioritize fluency over accuracy, leading to coherent but possibly incorrect statements. The tradeoff between generating creative vs accurate responses is a delicate balancing act.
Input Context: Giving clear, precise, and detailed prompts ensures the model has a better understanding of what you’re asking. Ambiguous or missing context can lead to misunderstandings, resulting in inaccurate responses. For instance, if you ask an LLM whether cats can speak English without mentioning that you’re referring to a cartoon, the model might give a completely different (and inaccurate) answer.
How Can We Reduce Hallucinations?
To minimize hallucinations, users can take several steps when interacting with LLMs:
Clear and Specific Prompts: This helps the model generate more relevant and accurate responses. For example, instead of a vague question like “What happened in World War II?” you could ask for a detailed summary, specifying key events and causes.
Active Mitigation Strategies: Adjusting certain settings of the LLM, like the temperature parameter, can help control the randomness of the output. A lower temperature typically results in more focused, predictable answers, while a higher temperature might introduce more creative but potentially less accurate responses.
Multi-shot Prompting: Providing the LLM with multiple examples of the type of output you’re looking for can help clarify the context and the model’s expectations. For example, showing a few examples of how you’d like the output formatted or styled can help guide the model in the right direction.
IBM’s Pillars of Trust
IBM takes a systematic approach to ethical AI with its Pillars of Trust, which focus on key aspects necessary for building trustworthy AI:
- Explainability – AI should be able to explain how and why it arrived at a decision.
- Fairness – AI must treat all individuals and groups equitably.
- Robustness – AI systems should be resilient to unexpected conditions, including adversarial attacks.
- Transparency – There should be openness about how AI systems are designed, developed, and function.
- Privacy – AI systems must prioritize and safeguard user data and privacy.
IBM has developed various tools to support these pillars:
- AI Explainability 360: Helps interpret and explain AI models.
- AI Fairness 360: Offers tools to detect and reduce bias in AI systems.
- Adversarial Robustness 360: Strengthens AI against adversarial attacks.
- AI Fact Sheets 360: Promotes transparency by documenting AI models and their performance.
- AI Privacy 360: Ensures privacy protection within AI systems.
Microsoft’s Ethical AI Framework
Microsoft focuses on a holistic and iterative approach to ethical AI, emphasizing the involvement of a broad group of stakeholders:
- Human-in-the-loop systems
- Continuous monitoring and improvement: Regular assessments and audits help ensure that AI systems remain aligned with ethical standards.
- Algorithmic Impact Assessments (AIA): These assessments identify and mitigate biases before AI systems are deployed.
- Microsoft’s Responsible AI Standard: A framework outlining accountability measures, transparency, and fairness.
Additionally, Microsoft has established internal bodies like Microsoft’s 8th Committee, which provides guidance on ethical AI practices, ensuring compliance and responsible deployment.
Google’s AI Principles
Google’s approach is grounded in seven core principles that guide the development and deployment of AI:
- Be socially beneficial – AI should serve society and align with broadly accepted ethical principles.
- Avoid creating or reinforcing bias – Ensure fairness and prevent harmful biases.
- Be built and tested for safety – Take steps to mitigate risks and ensure AI’s safe use.
- Be accountable to people
- Incorporate privacy design principles
- Uphold high standards of scientific excellence
- Be made available for uses that align with these principles – Limit AI applications to those that align with these ethical guidelines.
Google also has a review process for evaluating AI projects, ensuring that each one is assessed for ethical risks and compliance with its principles.
Collaboration for Ethical AI
In addition to their internal frameworks, these companies are collaborating externally to promote responsible AI. For example, IBM and Meta co-launched the AI Alliance, which brings together organizations from various sectors to foster trustworthy, inclusive, and responsible AI development. Consulting firms like Deloitte and PwC are also helping businesses implement ethical AI practices, with training programs and workshops focused on raising awareness about the ethical implications of AI.
Key Takeaways:
- IBM focuses on trust through its five pillars: explainability, fairness, robustness, transparency, and privacy.
- Microsoft promotes continuous improvement and human oversight, with regular audits and algorithmic impact assessments.
- Google emphasizes social benefit, safety, fairness, and accountability in its AI principles.
Evaluating AI Solutions:
To ensure the ethical principles are followed, companies can use design thinking activities, one of which is dichotomy mapping:
- Dichotomy Mapping involves:
- Listing Features & Benefits
- Identifying Potential Harms: After listing features and their benefits, companies must assess if any of these features could cause harm. For example, issues could arise if data is insecure, if it’s sold to third parties, or if differently-abled individuals are excluded from using the system.
Guardrails and Fixing Problems:
Once potential issues are identified, companies can implement guardrails to ensure ethical behavior:
- Guardrails are essentially hard boundaries that the AI system cannot cross. An example of this might be prohibiting the sale of customer data to advertisers.
Other strategies include:
- Diverse Data Sets: Ensuring that the data used to train AI models represents all user groups fairly and without bias.
- Tools to Detect Bias: Tools like IBM’s AI Fairness 360 can help detect and mitigate bias in machine learning models, ensuring fairness and compliance with ethical standards.
- Privacy Considerations: Using tools to help adhere to privacy regulations and detect uncertainties or gaps in the model’s decision-making.


